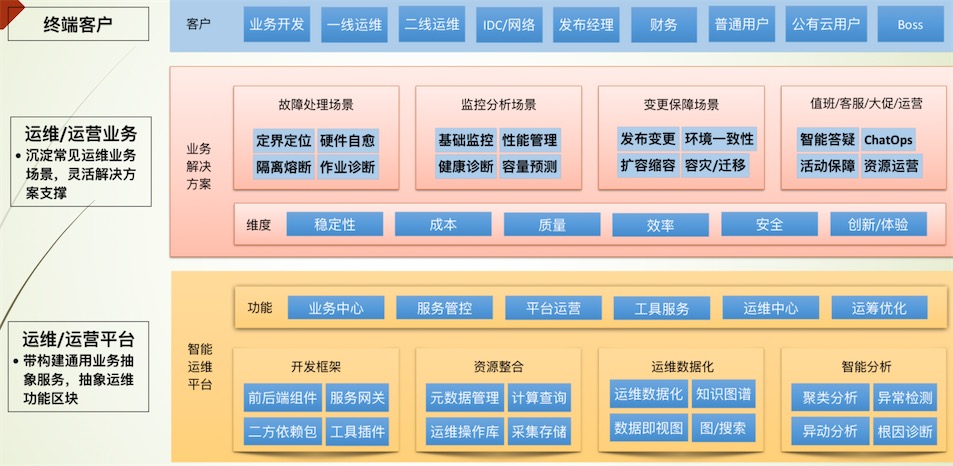
各公司智能运维 AIOPs架构分析和对比
[TOC]
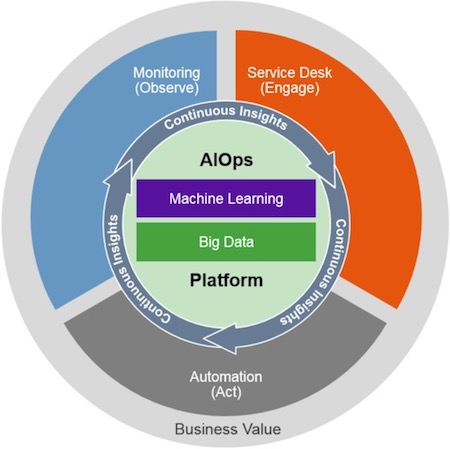
数据驱动的智能运维平台 ★★★★★
什么是AIPOs
在定义 AIOps 时画了一张图,除了中间有机器学习、BigData、Platform 外,外层的内容就是监管控,这也就是做 AIOps 的目的。只不过是在做监管控时,要使用一些新的方式,以减轻运维的工作量。
机器学习的运用算法分类
这个可以用来做系统设计的参考
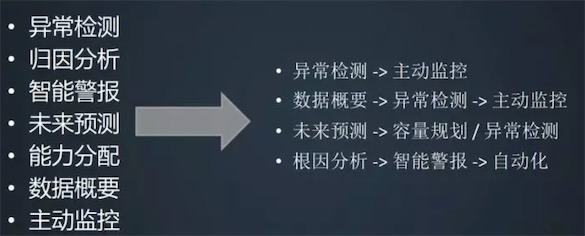
典型应用场景
主要包含:时序预测、异常检测、模式聚类。
时序预测
(eg:Holt-Winters),开源选择:

异常检测
分析思路:Basic 采用的是四分位方法,Agile 用的是 SARIMA 算法,Robust 用的是趋势分解,Adaptive 在我看起来,采用的是 sigma 标准差。如下图:

对于异常检测的开源库选择,有些是原子的,有些是组合的。Etsy 的 skyline 是比较高级的场景,里面带有数据存储、异常检测分析、告警等;Twitter、Netflix、Numenta 是纯粹的机器学习算法库,没有任何附加内容;Yahoo 的 egads 库可以算是异常检测的原子场景,比 Twitter 和 Netflix 层级稍高。开源选择:

另外这部分,还提到了很多场景案例的分析和对比。
监控的目标需要直达业务结果,业务量下跌即为出现故障,虽然故障可能不是由于系统本身引起,但仍需要发现并定位该故障。如此将一个对业务的监控通过以下流程进行转换,首先对故障进行等级定义,对时间序列的业务指标监控,定位异常点,做出故障通告。
模式聚类
第一个,像 Num、Date、IP、ID 等都是运维 IT 日志里一定会出现的,但在关注模式时不会关注这些。因此,可以在开始就把这些信息替换,节省工作量。
第二个是对齐,对齐也是耗资源的,如何减少对齐的时候强行匹配资源呢?可以开始先走一个距离极其小的聚类,这样每一类中的原始文本差异非常小。此时意味着第二步得到的最底层聚类去做对齐时,在这个类里的对齐耗损就会非常小,可以直接做模式发现。
到第四步的时候,虽然还是聚类,但是消耗的资源已经非常少,因为给出的数据量已经很小,可以快速完成整个速度的迭代。

##《企业级 AIOps 实施建议》白皮书 ★★★★★
AIOPs的白皮书,关键内容:
能力框架
学件抽象
学件,亦称 AI 运维组件,类似程序中的 API 或公共库,但 API 及公共库不含具体业务数据,只是某种算法,而 AI 运维组件(或称学件),则是在类似 API 的基础上,兼具对某个运维场景智能化解决的“记忆”能力,将处理这个场景的智能规则保存在了这个组件中。学件(Learnware)= 模型( model ) + 规 约 ( specification ) , 具 有 可 重 用 、 可 演 进 、 可 了 解 的 特 性 。
学件类似于百度AIOPs的机器人,但是,角度不同,含义也不同。
能力分级

整体架构

- “可重用”的特性使得能够获取大量不同的样本;
- “可演进”的特性使得可以适应环境的变化;
- “可了解”的特性使得能有效地了解模型的能力。
关键运维场景和经历阶段
见百度部分的场景图
平台架构
整体功能架构(模块)
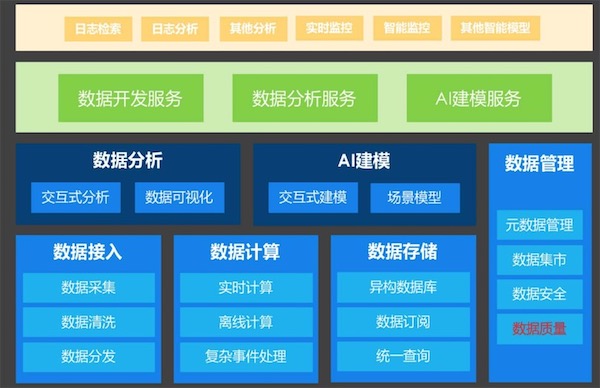
AI部分架构
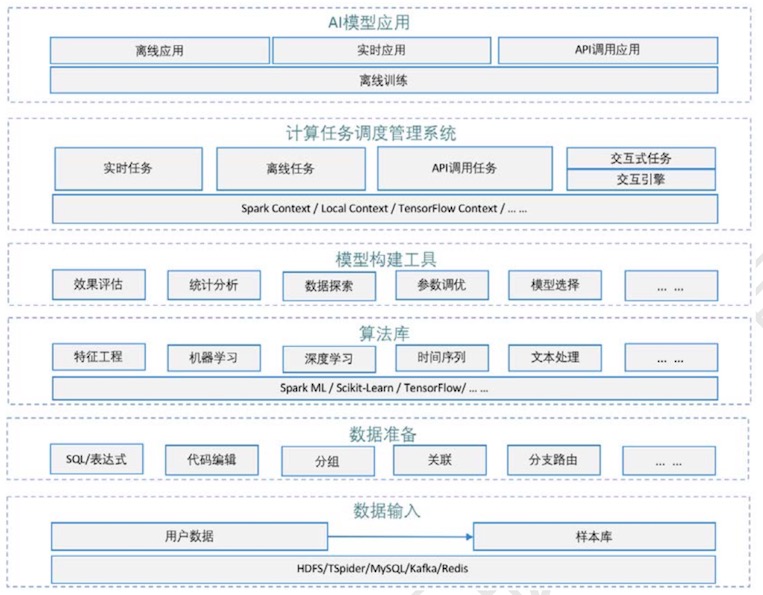
如上面的两张架构图,具体的工具或者产品应具备以下功能或模块:
- 交互式建模功能:该功能支持用户在平台上交互式的进行模型的开发调试,通过简单的方法配置完成模型的构建。
- 交互式建模功能:该功能支持用户在平台上交互式的进行模型的开发调试,通过简单的方法配置完成模型的构建。
- 算法库:用户可以在算法库中找到常见常用的算法直接使用,算法按照用途分类, 以供用户方便的使用。
- 算法库:用户可以在算法库中找到常见常用的算法直接使用,算法按照用途分类, 以供用户方便的使用。
- 样本库:样本库用于管理用户的样本数据,供用户建模时使用,支持样本的增删改查等基本操作。
- 样本库:样本库用于管理用户的样本数据,供用户建模时使用,支持样本的增删改查等基本操作。
- 数据准备:该功能支持用户对数据进行相关的预处理操作,包括关联、合并、分支路由、过滤等。
- 数据准备:该功能支持用户对数据进行相关的预处理操作,包括关联、合并、分支路由、过滤等。
- 灵活的计算逻辑表达:在基本常用的节点功能之外,用户还需要自由的表达一些计算逻辑,该需求主要是通过让用户写代码或表达式来支持。
- 灵活的计算逻辑表达:在基本常用的节点功能之外,用户还需要自由的表达一些计算逻辑,该需求主要是通过让用户写代码或表达式来支持。
- 可扩展的底层框架支持:平台本身要能够灵活的支持和兼容多种算法框架引擎,如Spark、TensorFlow 等,以满足不同的场景以及用户的需求。
- 可扩展的底层框架支持:平台本身要能够灵活的支持和兼容多种算法框架引擎,如Spark、TensorFlow 等,以满足不同的场景以及用户的需求。
- 数据分析探索:该功能是让用户能够方便快捷地了解认识自己的数据,用户只有基于对数据充分的认识与理解,才能很好的完成模型的构建。
- 模型评估:对模型的效果进行评估的功能,用户需要依据评估的结论对模型进行调整。
- 参数以及算法搜索:该功能能够自动快速的帮助用户搜索算法的参数,对比不同的算法,帮助用户选择合适的算法以及参数,辅助用户建模。
- 场景模型:平台针对特定场景沉淀的解决方案,这些场景都是通用常见的,用户可以借鉴参考相关的解决方案以快速的解决实际问题
- 实验报告:模型除了部署运行,相关挖掘出来的结论也要能够形成报告,以供用户导出或动态发布使用。
- 模型的版本管理:模型可能有对个不同的版本,线上运行的模型实例可能分属各个不同的版本,版本管理支持模型不同版本构建发布以及模型实例版本切换升级等。
- 模型部署应用:模型构建完成后需要发布应用,模型部署应用功能支持模型的实例化,以及相关计算任务的运行调度管理。
- 数据质量保障:全链路的数据监控,能够完整的掌控数据的整个生命周期,具备对丢失的数据执行回传补录的能力,保障数据的可用性。
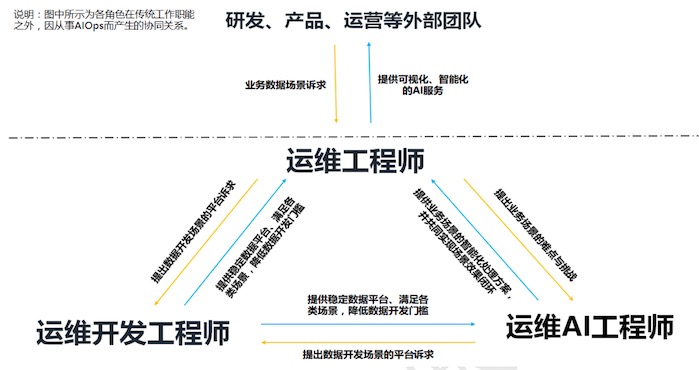
AIOPs的团队角色
常见场景和分类
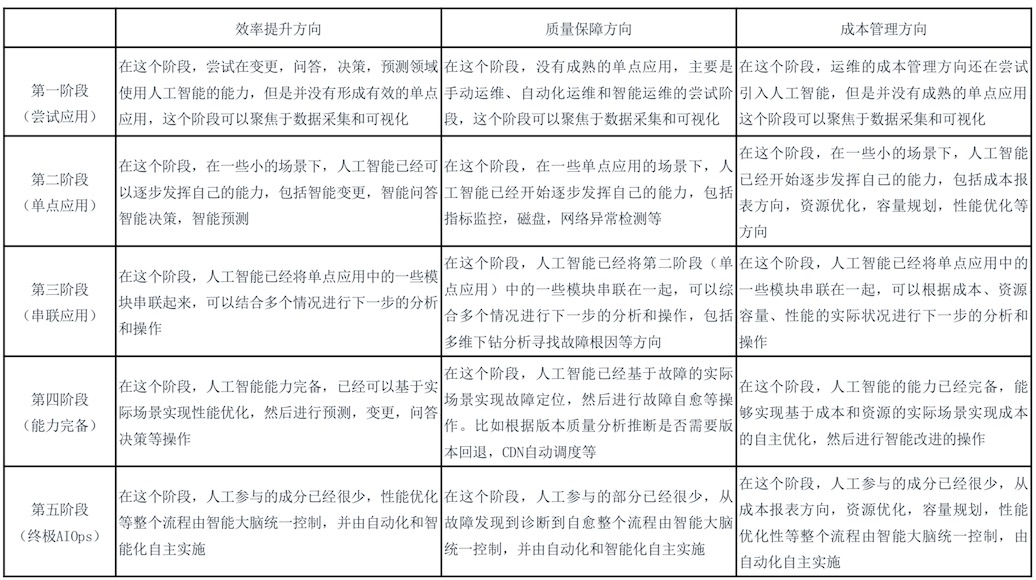
效率提升、质量保障、成本管理。我们的重点在于质量管理,还有一部分的效率提升。

3个场景的五个阶段
详见附件中的表格。
实施和关键技术
数据平台、需要用到的关键算法。—重点在于怎么对算法进行抽象,得到算法的公共层,从而各个垂直场景中都可以使用。
应用案例:
- 时间序列异常检测(腾讯):有监督算法+无监督算法。
- 根源告警(京东)
- 单机房故障自愈(百度):详见
调度部分
面向 AIOps 的算法技术
运维场景通常无法直接基于通用的机器学习算法以黑盒的方式解决,因此需要一些面向AIOps 的算法技术,作为解决具体运维场景的基础。有时一个算法技术还可用于支撑另外一个算法技术。 常见的面向 AIOps 的算法技术包括:
- 指标趋势预测:通过分析指标历史数据,判断未来一段时间指标趋势及预测值,常见有
Holt-Winters、时序数据分解、ARIMA等算法。该算法技术可用于异常检测、容量预测、容量规划等场景。
- 指标趋势预测:通过分析指标历史数据,判断未来一段时间指标趋势及预测值,常见有
- 指标聚类: 根据曲线的相似度把多个 KPI 聚成多个类别。该算法技术可以应用于大规模的指标异常检测:在同一指标类别里采用同样的异常检测算法及参数,大幅降低训练和检测开销。常见的算法有
DBSCAN,K-medoids,CLARANS等,应用的挑战是数据量大,曲线模式复杂。
- 指标聚类: 根据曲线的相似度把多个 KPI 聚成多个类别。该算法技术可以应用于大规模的指标异常检测:在同一指标类别里采用同样的异常检测算法及参数,大幅降低训练和检测开销。常见的算法有
- 多指标联动关联挖掘: 多指标联动分析判断多个指标是否经常一起波动或增长。该算法技术可用于构建故障传播关系,从而应用于故障诊断。常见的算法有
Pearson correlation,Spearman correlation,Kendall correlation等,应用的挑战为 KPI 种类繁多,关联关系复杂。
- 多指标联动关联挖掘: 多指标联动分析判断多个指标是否经常一起波动或增长。该算法技术可用于构建故障传播关系,从而应用于故障诊断。常见的算法有
- 指标与事件关联挖掘: 自动挖掘文本数据中的事件与指标之间的关联关系( 比如在程序 A 每次启动的时候 CPU 利用率就上一个台阶)。该算法技术可用于构建故障传播关系,从而应用于故障诊断。常见的算法有
Pearson correlation,J-measure,Two-sample test等,应用的挑战为事件和 KPI 种类繁多,KPI 测量时间粒度过粗会导致判断相关、先后、单调关系困难。
- 指标与事件关联挖掘: 自动挖掘文本数据中的事件与指标之间的关联关系( 比如在程序 A 每次启动的时候 CPU 利用率就上一个台阶)。该算法技术可用于构建故障传播关系,从而应用于故障诊断。常见的算法有
- 事件与事件关联挖掘: 分析异常事件之间的关联关系,把历史上经常一起发生的事件关联在一起。该算法技术可用于构建故障传播关系,从而应用于故障诊断。常见的算法有
FP-Growth,Apriori,随机森林等,但前提是异常检测需要准确可靠。
- 事件与事件关联挖掘: 分析异常事件之间的关联关系,把历史上经常一起发生的事件关联在一起。该算法技术可用于构建故障传播关系,从而应用于故障诊断。常见的算法有
- 故障传播关系挖掘:融合文本数据与指标数据,基于上述多指标联动关联挖掘、指标与事件关联挖掘、事件与事件关联挖掘等技术、由 tracing 推导出的模块调用关系图、辅以服务器与网络拓扑,构建组件之间的故障传播关系。该算法技术可以应用于故障诊断,其有效性主要取决于其基于的其它技术。
百度智能运维 ★★★★★
参考:
- 百度智能运维AIOPs技术沙龙关键PPT.pdf
- 百度智能运维的技术演进之路
- 百度智能运维 | 框架在手,AI我有
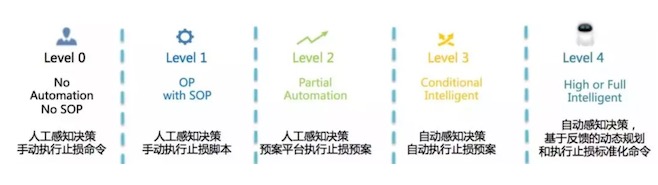
智能运维分级标准(阶段)
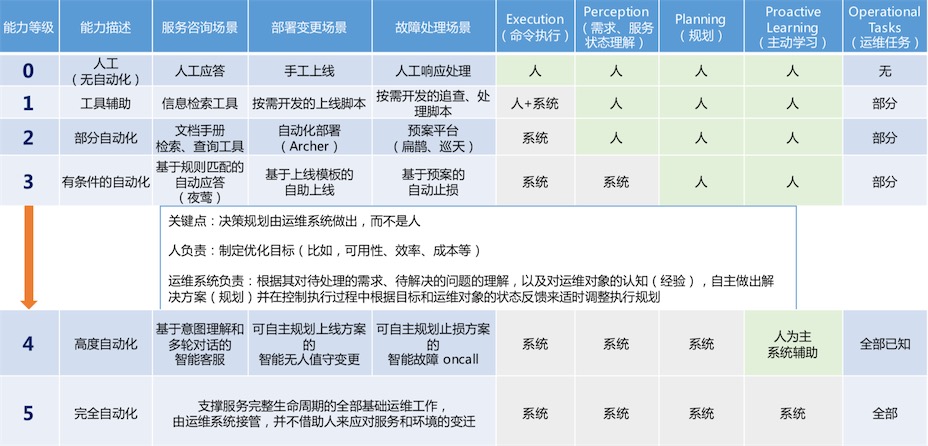
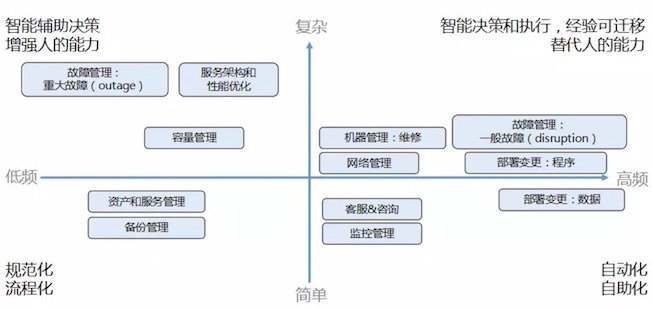
智能运维架构——场景象限划分
高频 X 复杂
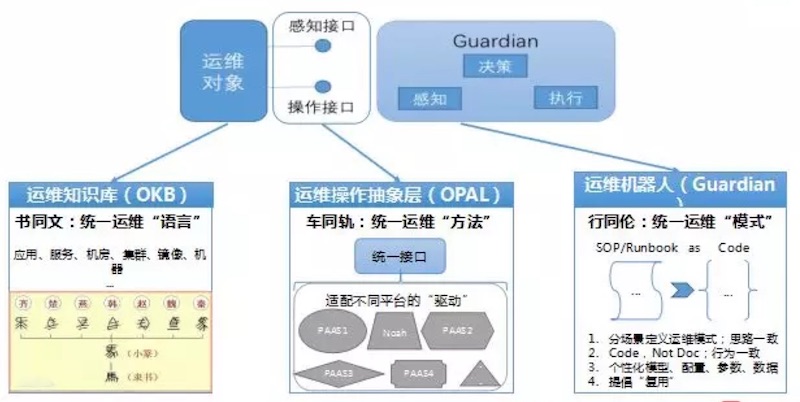
智能运维架构——工程思想
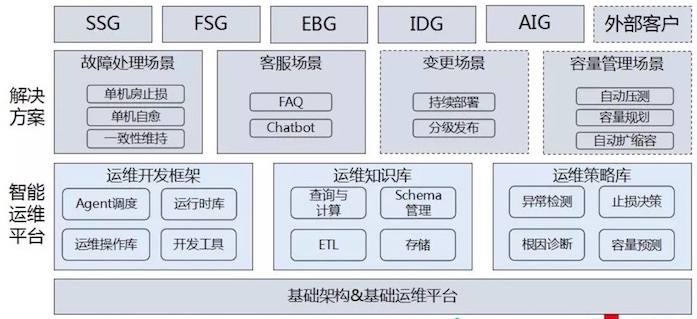
运维工程架构——整体框架
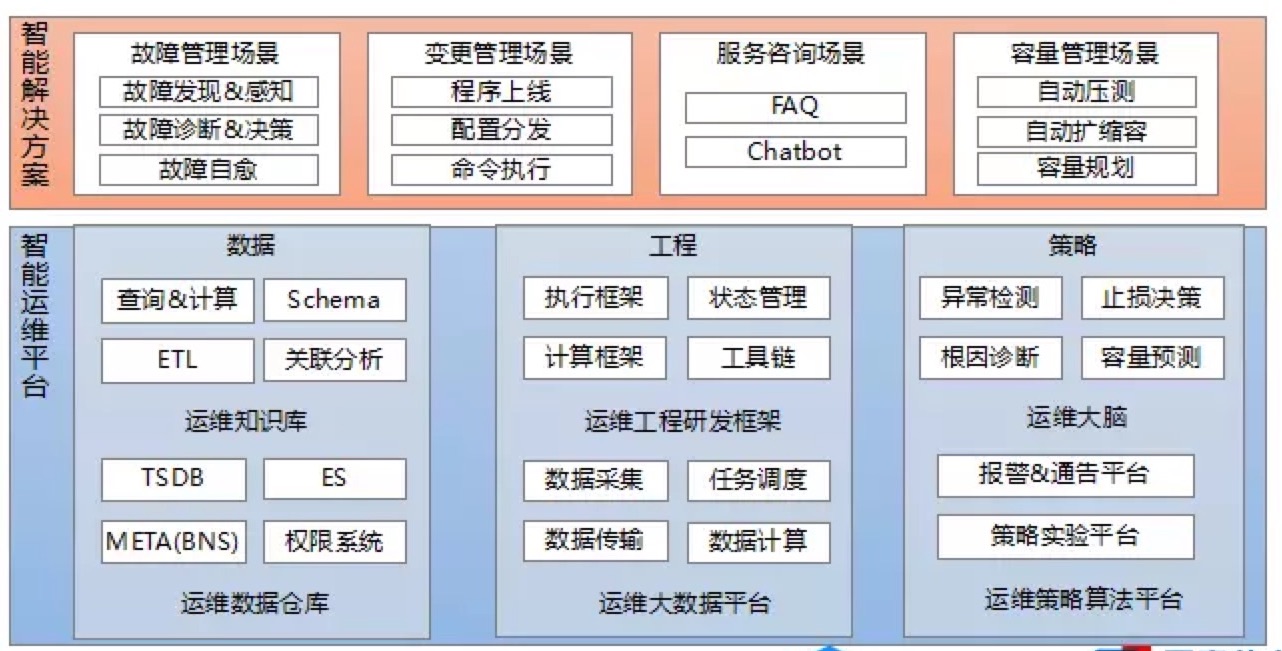
智能运维架构——技术栈(技术架构)
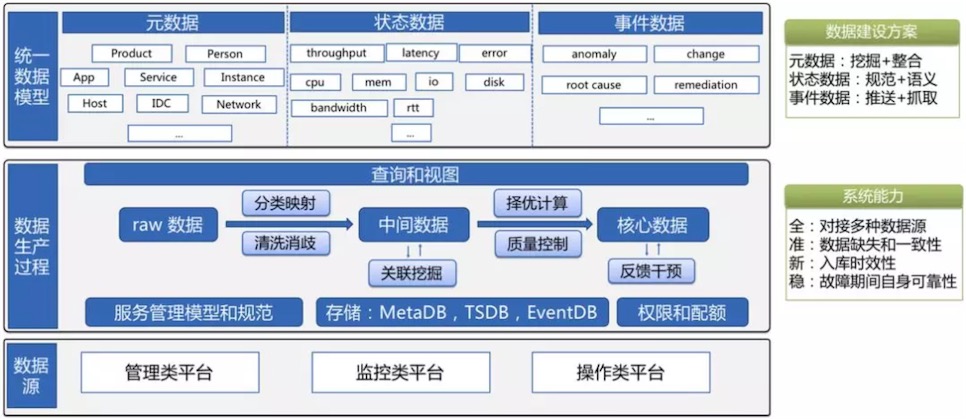
4.1 运维知识库(运维数据)
所有要处理的数据都来自知识库,以及所有处理后的数据也都会再进入到知识库中。知识库由三部分组成,分别是分为元数据(MetaDB)、状态数据(TSDB)和事件数据(EventDB)。持续的数据建设,是智能运维建设的关键。
4.2 运维工程研发框架
每个运维智能操作都可以分解成感知、决策、执行这样一个标准流程,这样一个流程叫做智能运维机器人。运维工程研发框架提供感知、决策、执行过程常用的组件,便于用户快速构建智能运维机器人。
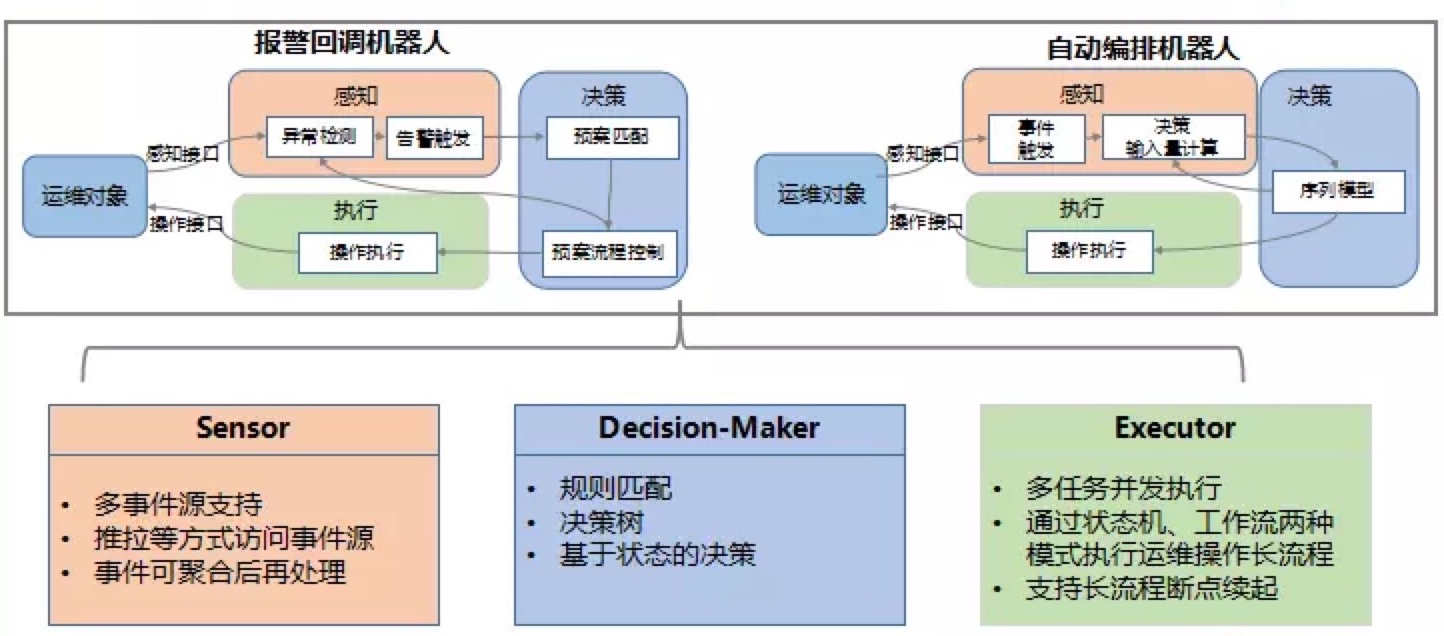
- 1、感知方面,智能异常检测算法替代过去大量误报漏报的阈值检测方法;
- 2、决策方面,具备全局信息、自动决策的算法组件替代了过去“老中医会诊”的人工决策模式;
- 3、执行方面,状态机等执行长流程组件的加入,让执行过程可定位、可复用。
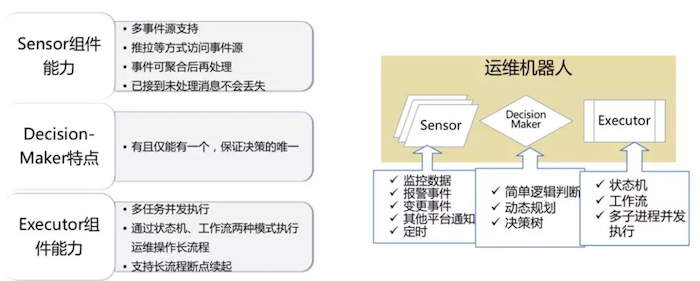
感知器是运维机器人的眼睛和耳朵。就像人有两个眼睛和两个耳朵一样。运维机器人也可以挂载多个感知器来获取不同事件源的消息,比如监控的指标数据或者是报警事件,变更事件这些,甚至可以是一个定时器。这些消息可以以推拉两种方式被感知器获取到。这些消息也可以做一定的聚合,达到阈值再触发后续处理。
决策器是运维机器人的大脑,所以为了保证决策的唯一,机器人有且只能有一个决策器。决策器也是使用者主要要扩展实现的部分。除了常见的逻辑判断规则之外,未来我们还会加入决策树等模型,让运维机器人自主控制决策路径。
执行器是运维机器人的手脚,所以同样的,执行器可以并行的执行多个不同的任务。执行器将运维长流程抽象成状态机和工作流两种模式。这样框架就可以记住当前的执行状态,如果运维机器人发生了故障迁移,还可以按照已经执行的状态让长流程断点续起。
4.3 运维开发框架
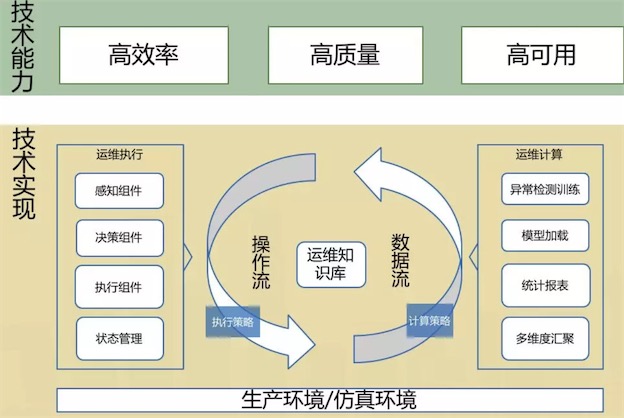
把线上环境看做一个黑盒服务,那么我们对它的操作无非读写两类:
- 所谓的写也就是操作控制流,是那种要对线上状态做一些改变的操作,我们常说的部署、执行命令,都属于这一类;
- 另一类是读,指的是数据流,也就是要从线上获取状态数据,并进行一些聚合统计之类的处理,我们常说的指标汇聚、异常检测、报警都在这个里面。
通过运维知识库,可以在这两种操作的基础上,封装出多种不同的运维机器人,对业务提供高效率、高质量以及高可用方面的能力。
4.3 运维大脑
运维大脑包括异常检测和故障诊断,这两个部分的共同基础是基本的恒定阈值异常检测算法。恒定阈值异常检测算法利用多种概率模型估计数据的概率分布,并由此产生报警阈值。
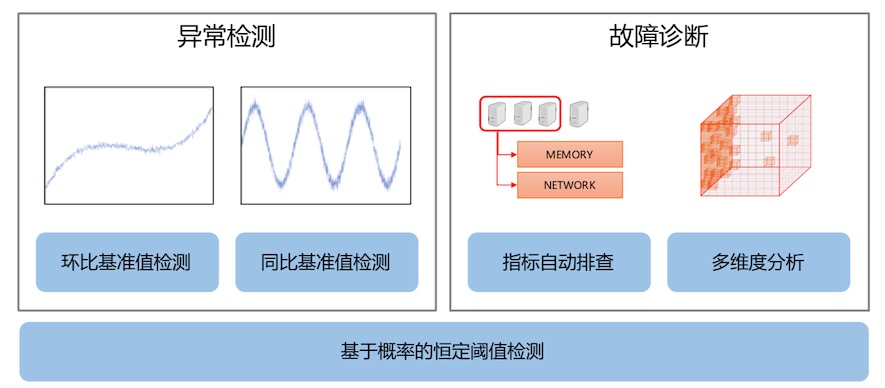
智能运维实践——故障管理解决方案
故障预防 —>故障发现 —>故障自愈 —>...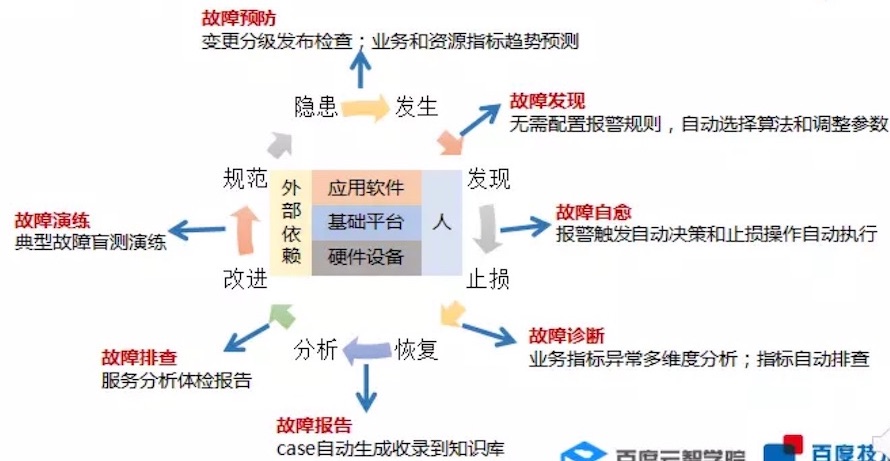
5.1故障预防
自动拦截异常变更。 —现阶段我们主要是通过人工流程来预防。
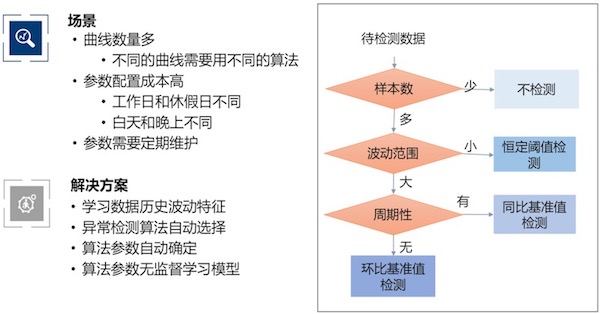
5.2 故障发现
算法自动选择:
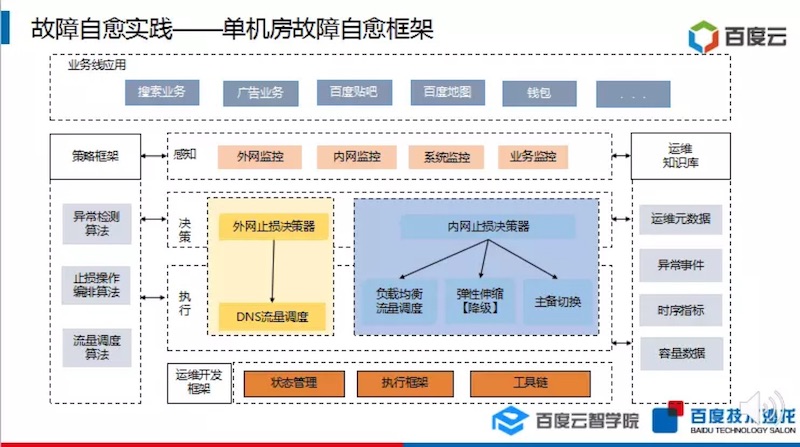
5.3 故障自愈
百度异常检测 ★★★★★
参考
百度智能运维实践之异常检测.pdf
异常检测
流程
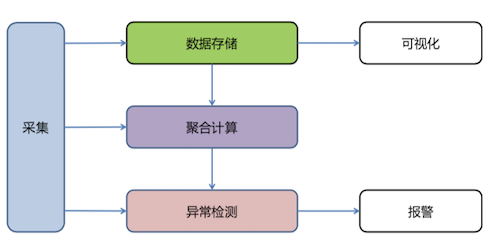
系统架构
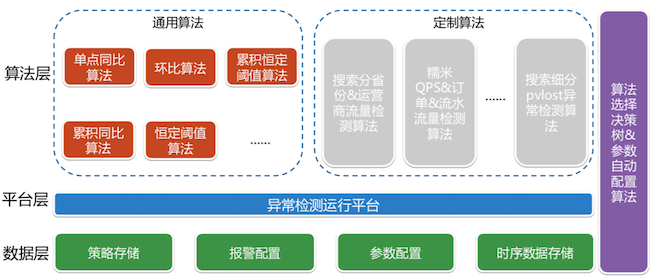
恒定阈值算法
累计恒定阈值 用来排除单点抖动。
突升突降算法
r空间:引入周期内累计值
同比算法
z空间:引入分布和数据标准化。 参考:三种常用数据标准化方法
时序数据存储及计算职责
使用专门的时序型数据库。
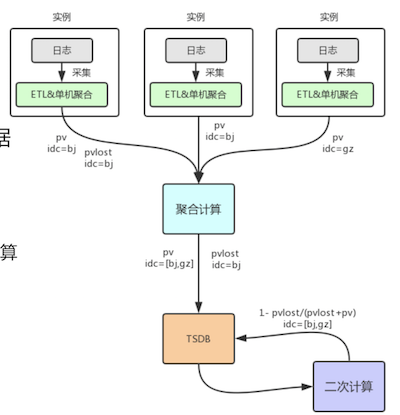
聚合计算实现
支持场景聚合函数sum/avg/...
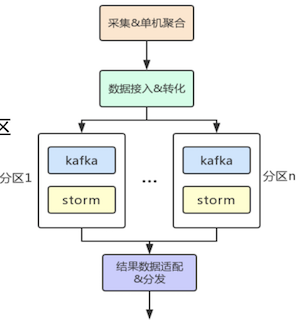
二次计算实现
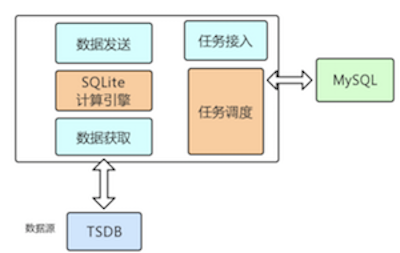
百度运维大数据存储平台设计与实践.pdf ★★★★
重点分析了物理层的设计,包括:
- 大规模时序数据的存储:层次存储结构:Hadoop--冷数据;Hbase—暖数据;Redis--热数据。
- 海量运维事件数据存储;EventDB
- 知识库(元数据管理):系统架构如下图:
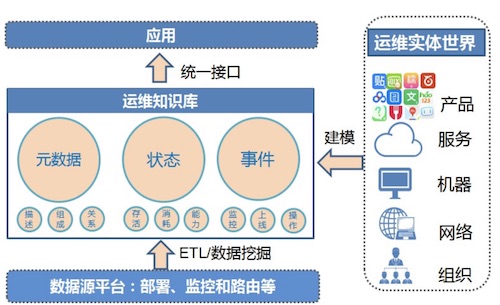
智能运维 | 单机房故障自愈,收藏这一篇就够了 ★★★★★
单机房故障止损的能力标准
故障自愈的技术架构
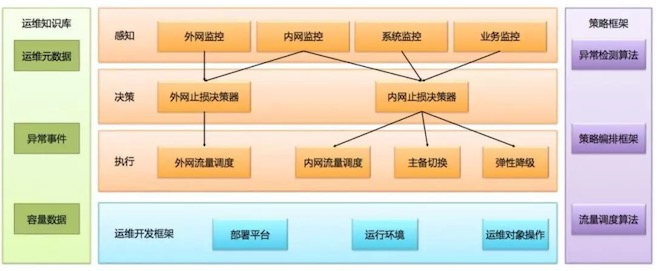
故障自愈的算法
基于容量水位的动态均衡(这个可能是BFE模型中的一部分)。智能IDC、专线路由都可以参考这个方案。
- 可以参考《企业级 AIOps 实施建议》白皮书中的
案例3
基于容量水位的动态均衡
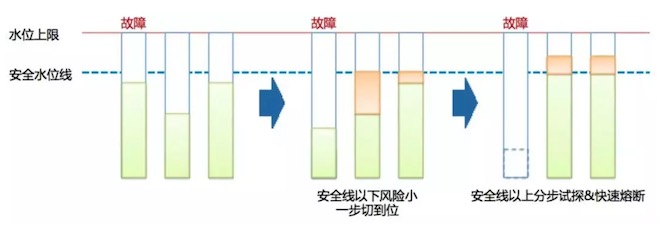
QQ20180703-204031 基于快速熔断的过载保护
在流量调度时,建立快速的熔断机制作为防止服务过载的最后屏障。一旦出现过载风险,则快速停止流量调度,降低次生故障发生的概率。
- 基于降级功能的过载保护
在流量调度前,如果已经出现对应机房的容量过载情况,则动态联动对应机房的降级功能,实现故障的恢复。
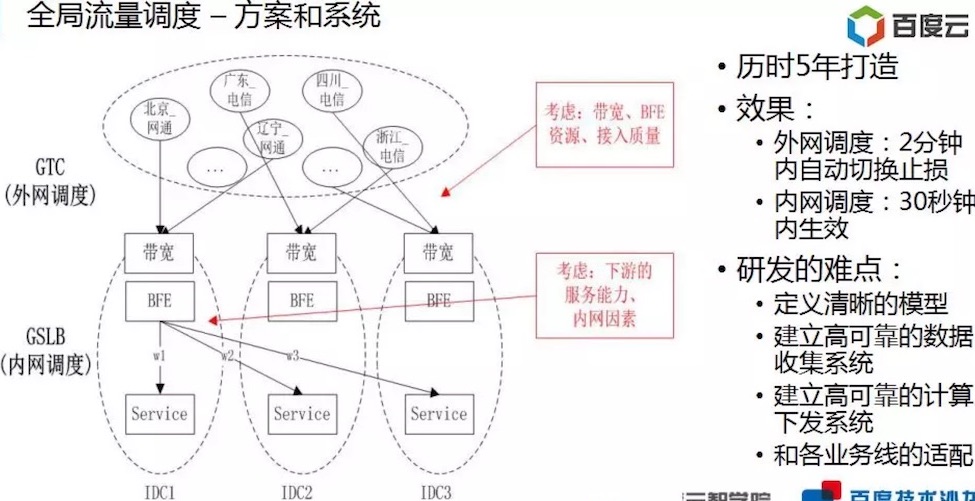
流量调度 ★★★★★
参考:百度智能运维AIOPs技术沙龙关键PPT
- 流量调度部分:重点在于模型的定义。
外卖订单量预测异常报警模型实践 ★★★★★
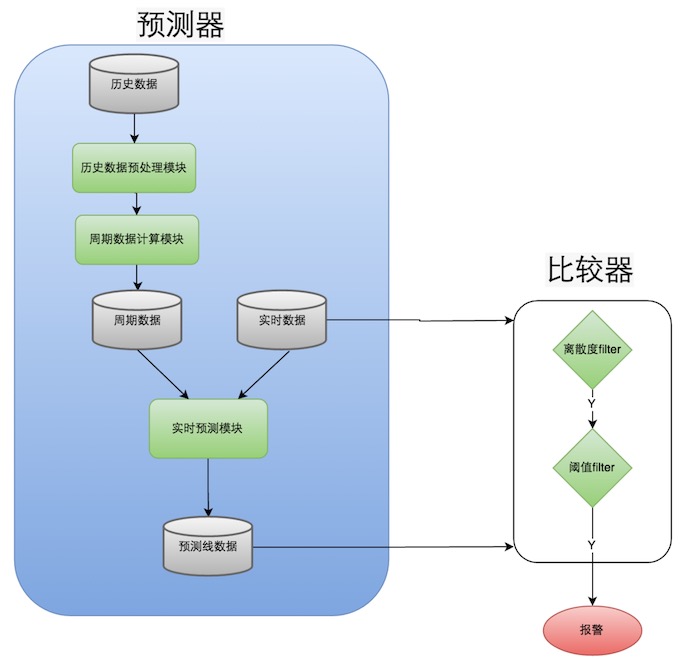
这篇介绍了Holt-Winters算法在订单异常检测中的应用。文章关键点在于: 1. 之前问过百度的智能运维,说曾经用过该算法,效果不是很好。但在该文章中效果看似还不错。其原因可能在,该文章对Holt-Winters算法进行了2种方式的精简和改进;这点值得借鉴。 2. 给出了异常检测模型,及模型内的各部件关系。 3. 给出了报警模型结构图。从该图可以看出,要实现整体过程,需要离线计算模块,这一块依赖于Hadoop,是我们还不具备的能力。
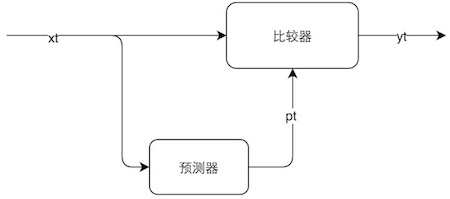
异常检测模型
基于预测的异常检测模型如下图所示,xt是真实数据,通过预测器得到预测数据,然后xt和pt分别作为比较器的输入,最终得到输出yt。yt是一个二元值,可以用+1(+1表示输入数据正常),-1(-1表示输入数据异常)表示。
预测器
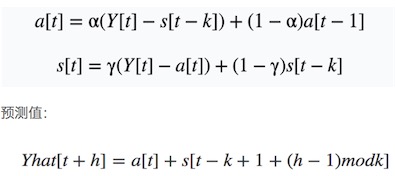
比较器模型
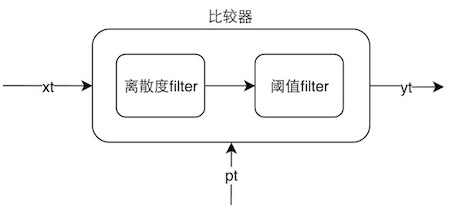
- 离散度Filter:根据预测误差曲线离散程度过滤出可能的异常点。一个序列的方差表示该序列离散的程度,方差越大,表明该序列波动越大。如果一个预测误差序列方差比较大,那么我们认为预测误差的报警阈值相对大一些才比较合理。离散度Filter利用了这一特性,取连续15分钟的预测误差序列,分为首尾两个序列(e1,e2),如果两个序列的均值差大于e1序列方差的某个倍数,我们就认为该点可能是异常点。
- 阈值Filter:根据误差绝对值是否超过某个阈值过滤出可能的异常点。利用离散度Filter进行过滤时,报警阈值随着误差序列波动程度变大而变大,但是在输入数据比较小时,误差序列方差比较小,报警阈值也很小,容易出现误报。所以设计了根据误差绝对值进行过滤的阈值Filter。阈值Filter设计了一个分段阈值函数y=f(x),对于实际值x和预测值p,只有当|x-p|>f(x)时报警。实际使用中,可以寻找一个对数函数替换分段阈值函数,更易于参数调优。
异常预警模型整体结构图
最终的外卖订单异常报警模型结构图如图所示,每天会有定时Job从ETL中统计出最近10天的历史订单量,经过预处理模块,去除异常数据,经过周期数据计算模块得到周期性数据。对当前时刻预测时,取60分钟的真实数据和周期性数据,经过实时预测模块,预测出当前订单量。将连续15分钟的预测值和真实值通过比较器,判断当前时刻是否异常。
阿里智能运维 ★★★★
运维体系职责
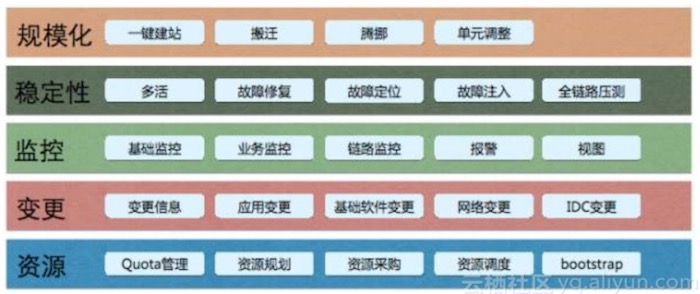
自动化是智能化的前提: 我认为智能化最重要的前提是自动化。如果你的系统还没有完成自动化的过程,我认为就不要去做智能化,你还在前面的阶段。智能化非常多的要求都是自动化,如果不够自动化,意味着后边看起来做了一个很好的智能化的算法等等,告诉别人我能给你很大的帮助,结果发现前面自动化过程还没有做完全。
阿里巴巴智能化运维五步走
在运维这五个领域,我们看到的一些可能性,包括我们正在做的事情。
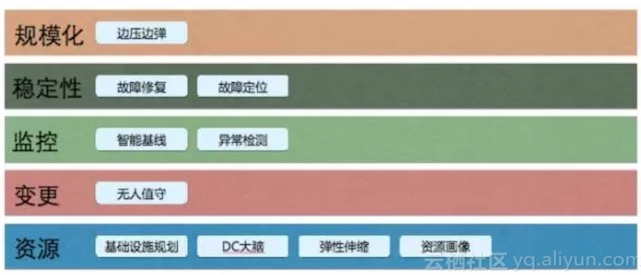
- 资源
- DC大脑,让控制更加智能化:谷歌的一篇文章,里面有一个消息透露,他们通过更好的智能化,去控制整个机房的智能等等。比如说控制空调的出口,就是风向往哪边吹,控制这个,然后为谷歌节省了非常多的钱,非常可观。
- 资源画像让资源更好搭配
- 监控AI化
- 智能报警:最火的领域。阿里在尝试的一个方向是让你不要去配,阿里根据分析来决定什么情况下需要报警。
- 异常检测直接影响到效率:很多公司都在做。
- 用智能化做好故障定位
智能运维整体架构——统一的大数据运营平台
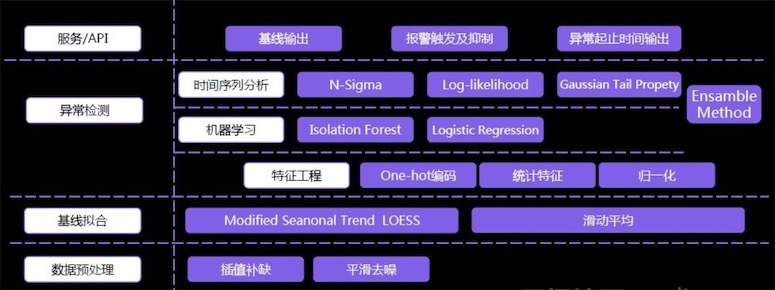
智能运维——异常检测算法架构
整体算法框架
整体算法框架如下图所示。
- 首先对数据进行预处理,包括差值补缺和平滑去噪。
- 然后基于优化后的时间序列分解Seanonal Trend LOESS方法进行基线拟合,滑动平均使曲线平滑。
- 然后结合时间序列分析、机器学习以及特征工程中的各种方法,判断一个时间片段是否需要报警。
- 开始设计时并未确定该算法应采取哪些方法,而是被阿里巴巴各行业的业务、形态各异的数据以及判断标准训练出来的。它的优势在于对各行业的数据有较高的适配性,对非技术性的曲线波动有较强的抗干扰能力。
- 此外,该算法会输出拟合的基线,并且内部系统中可以通过该基线提前100分钟预测趋势,当然距离越近的预测越准确,预测时会将历史波动和局部变化趋势都考虑在内,每个瞬间都会判断这个时刻是否需要报警。
- 出现报警后,可以回溯到该报警的开始时间和结束时间。由此达到整体的报警功能。
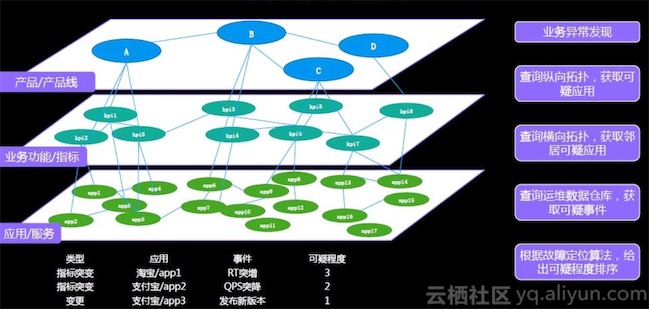
集群智能分析架构-异常分析
智能根因推荐
分析流程
人工智能驱动大数据
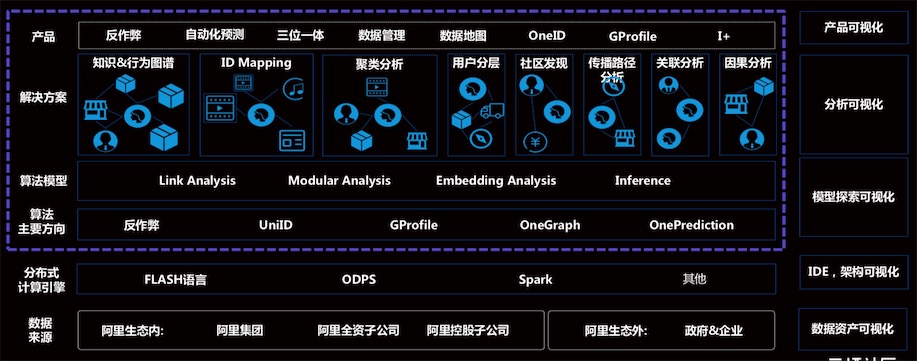
技术主要包含4部分:智能解决方案算法平台、 数据资产 管理平台、数据计算开发平台、数据采集管理平台。
算法平台架构
人工智能解决方案算法平台架构:
数据清洗层架构
整体结构
下图中,模型层对各算法进行了抽象,分为:规则、异常检测算法、监督&无监督算法、图算法等。

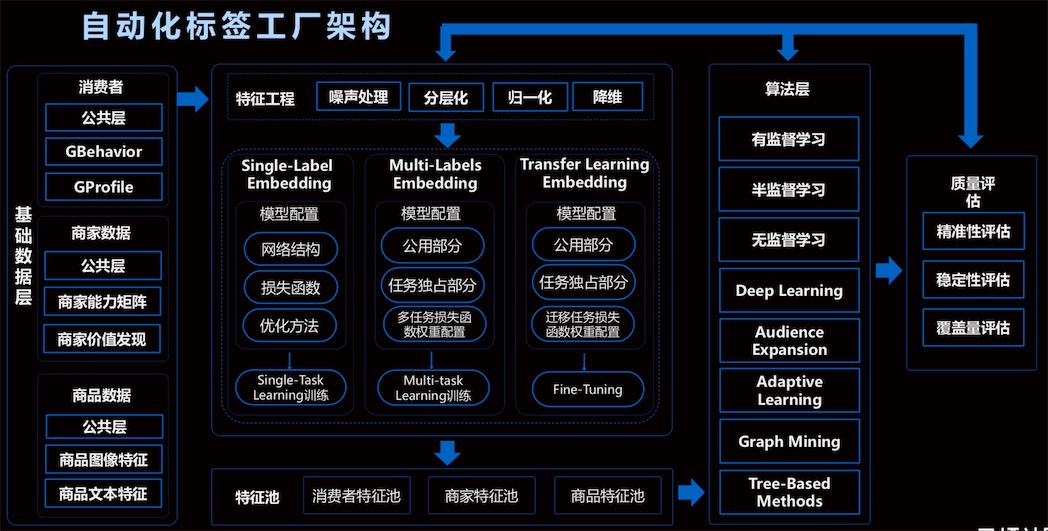
自动化标签工厂架构
流程:基础数据 --> 特征 --> 算法 --> 质量评估
参考
清华裴丹:AIOps落地路线图 ★★★★
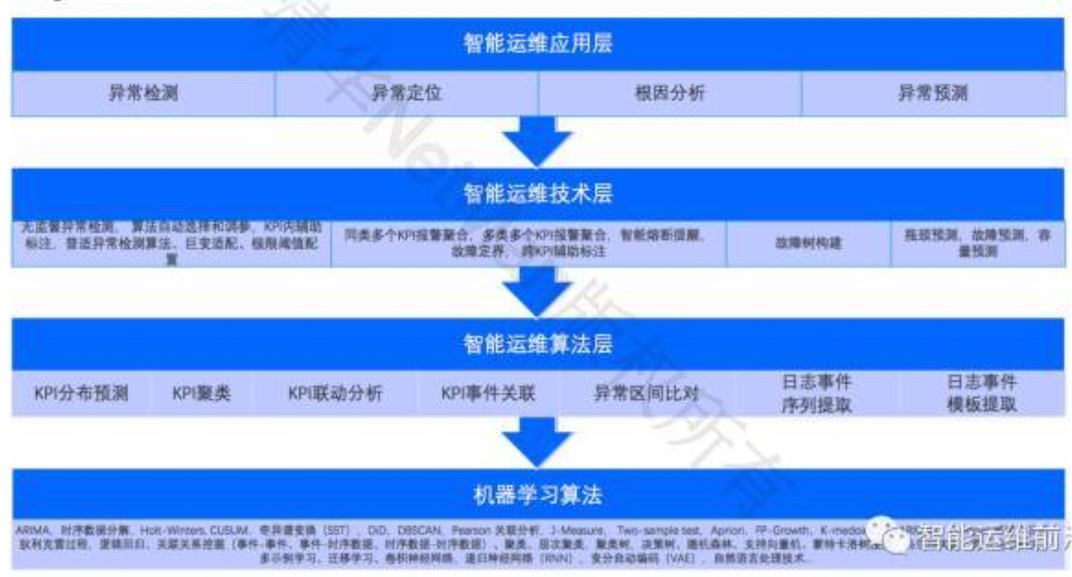
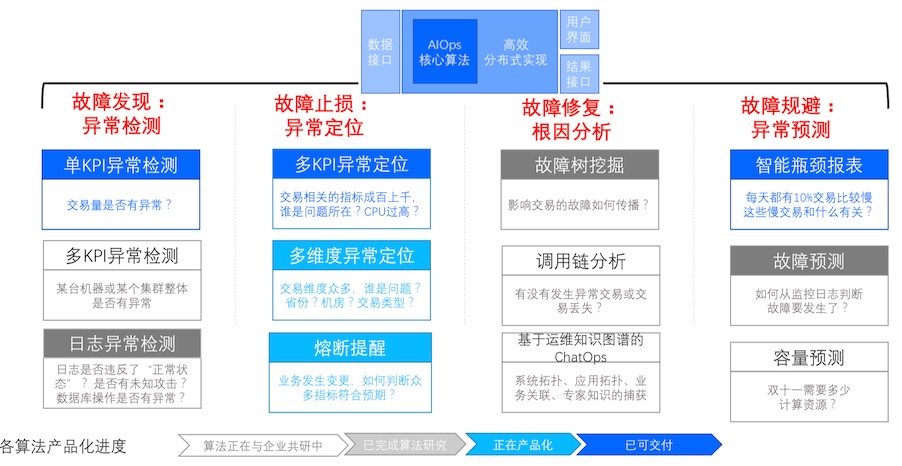
整体流程
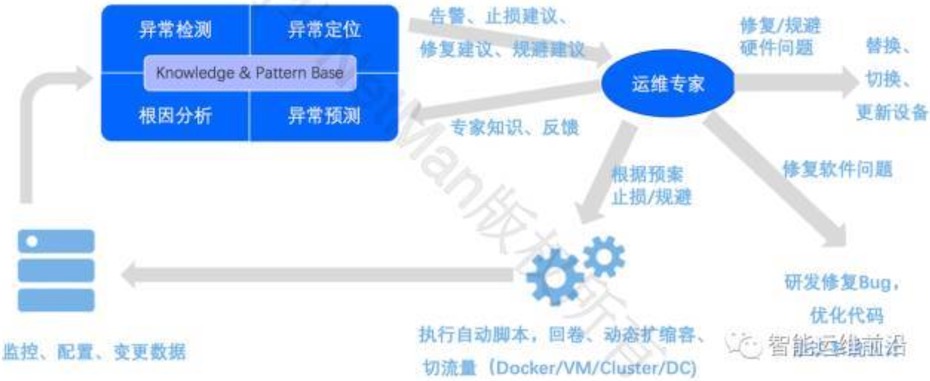
AIOps引擎 中的“异常检测”模块在检测到异常之后可以将报警第一时间报给运维人员,达到“故障发现”的效果;
“异常定位”模块达到“故障止损”的效果,它会给出一些止损的建议,运维专家看到这个定位之后也许他不知道根因,但是他知道怎么去根据已有的预案来进行止损,然后再执行自动化的脚本。如果是软件上线导致的问题我们回卷,如果业务不允许回卷就赶紧发布更新版本;如果是容量不够了,那我们动态扩容;如果部分软硬件出问题了,我们切换一下流量等等。
AIOps引擎中的“根因分析”模块会找出故障的根因,从而对其进行修复。如果根因是硬件出了问题,像慢性病一样的问题,那我们可以让我们的运维人员去修复。
- 同时,AIOps 引擎中的“异常预测模块”能够提前预测性能瓶颈、容量不足、故障等,从而实现“故障规避”。比如,如果我们预测出来了设备故障的话,那么可以更新设备;如果说我们发现性能上的瓶颈是代码导致的,那就交给研发人员去修改。
核心的AIOps的引擎会积累一个知识库,从里边不断的学习。也就是说监控数据会给AIOps提供训练数据的基础,然后专家会反馈一部分专家知识,上图是我展望的AIOps大概的体系结构,这里面关键的一点是,我们还是离不开运维专家的。最终的止损、规避的决策、软件的代码修复以及设备的更换还是要靠人来做的,但是机器把绝大部分工作都做了,包括异常检测、异常定位、根因分析、异常预测。
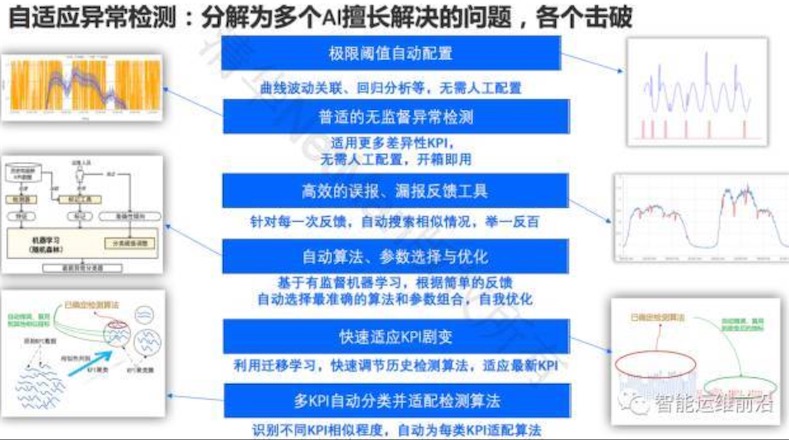
AI 擅长解决问题

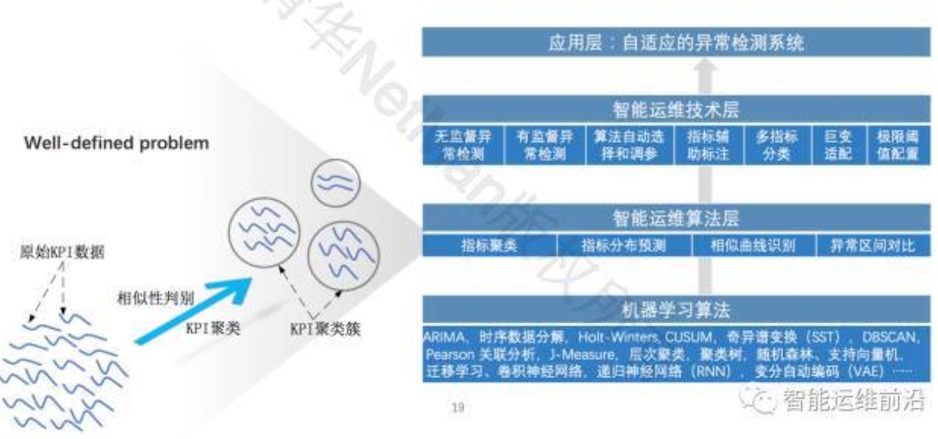
架构(技术路线图)
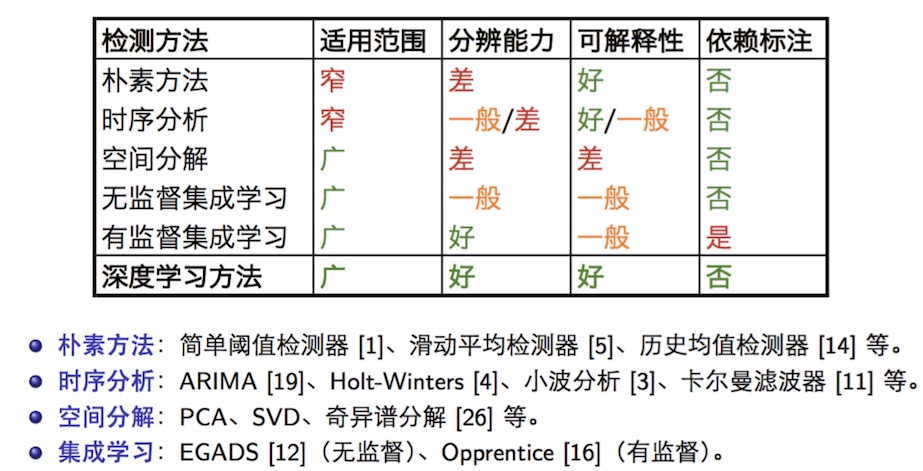
各类算法对比
算法产品
异常检测
故障发现
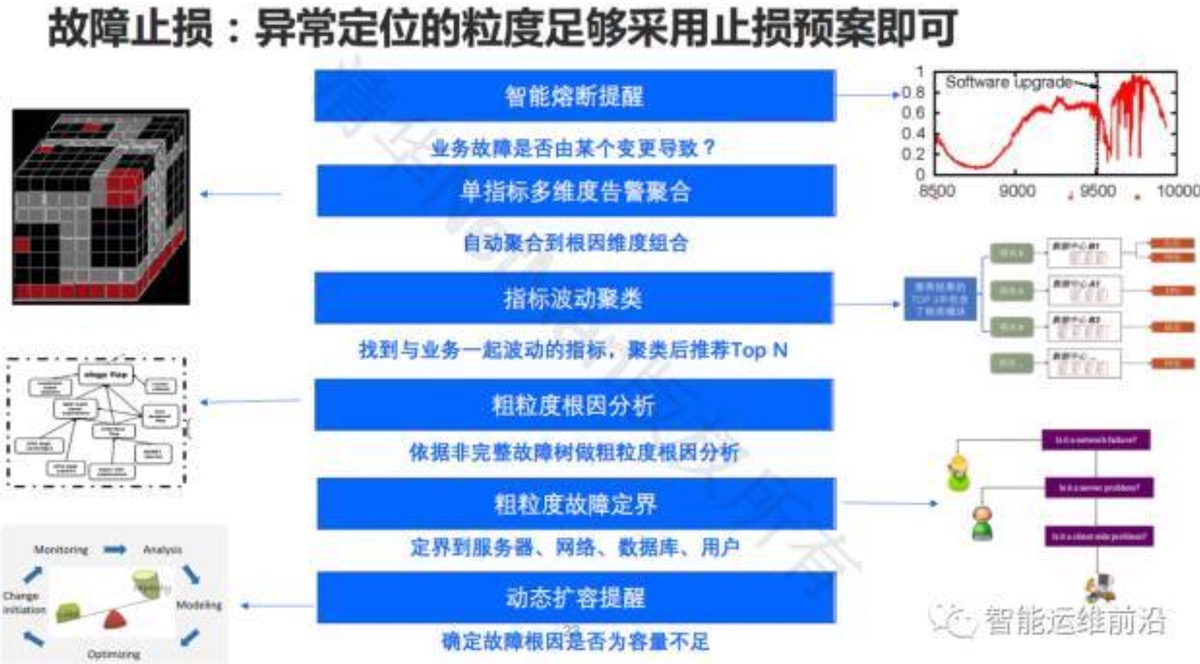
故障止损
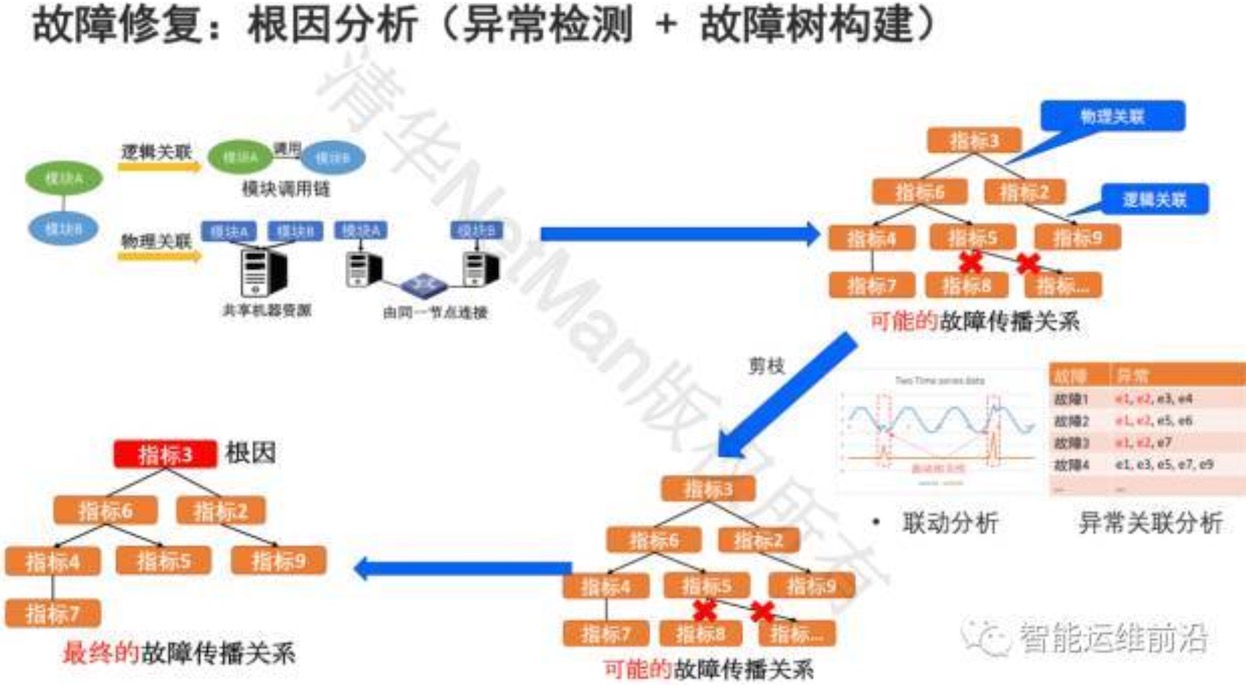
故障修复
参考
- 清华裴丹分享AIOps落地路线图,看智能运维如何落地生根
- 6、裴丹-AIOps在传统行业的落地探索.pdf
腾讯AIOPs ★★★★★
智能运维思路
整体架构
运维平台整体架构
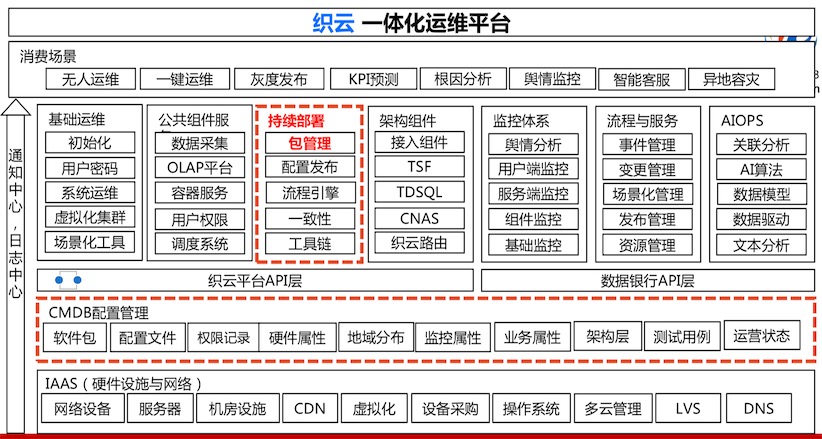
技术架构
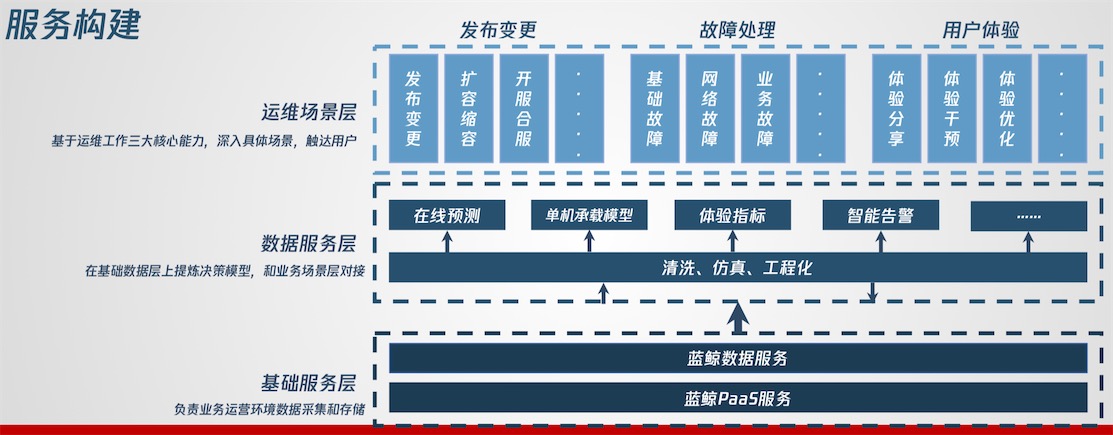
服务构建
智能运营白皮书用于衡量智能化产品建设的水平,白皮书中定义了:
- 三个阶段:半智能、浅智能、智能
- 六项能力:感知、分析、决策、执行、呈现、干预
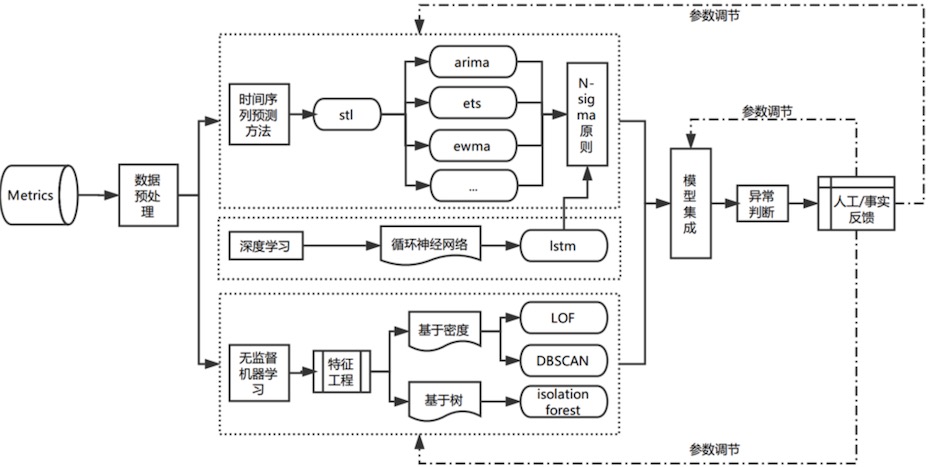
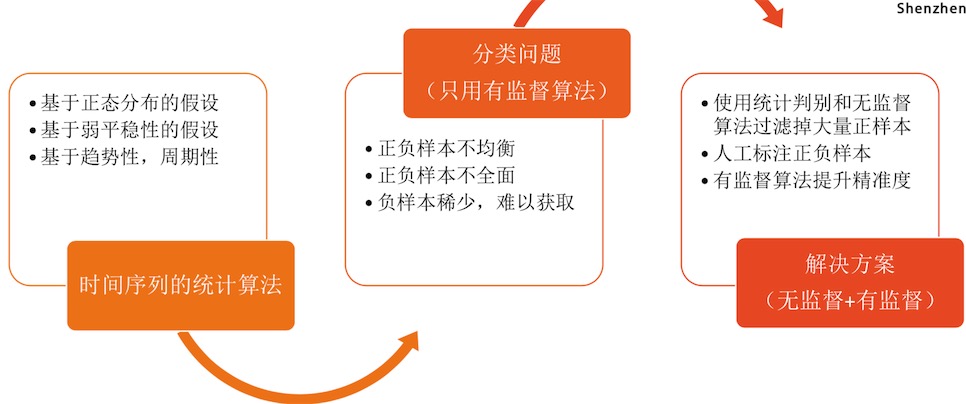
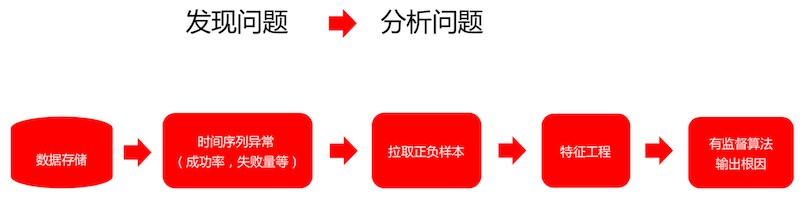
时间序列异常检测
3类算法

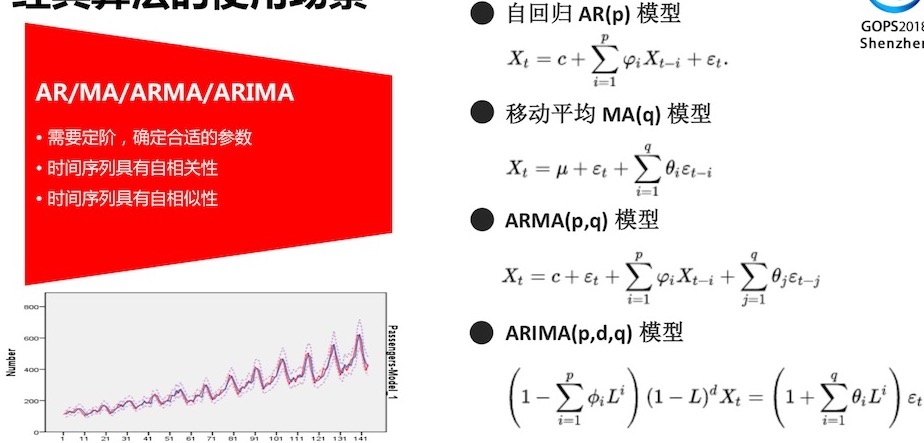
经典算法的使用场景:AR/MA/ARMA/ARIMA
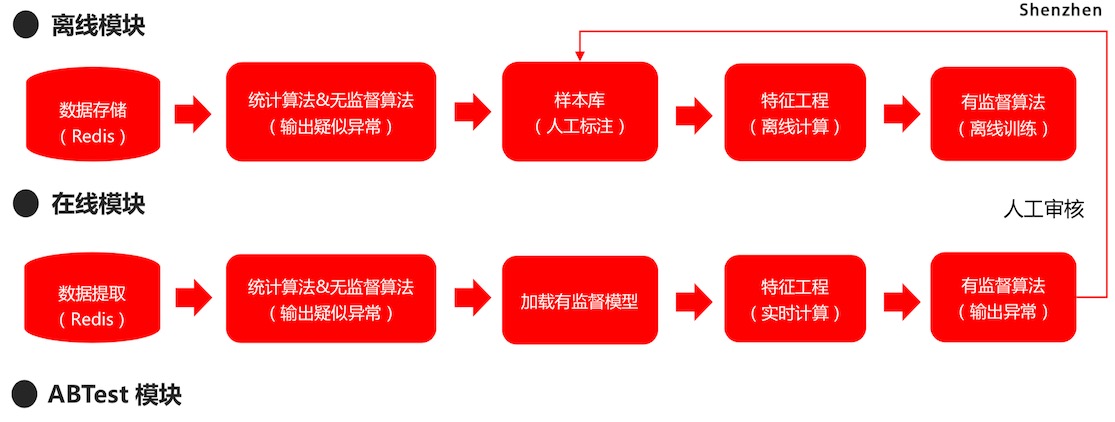
时间序列异常检测的技术框架
3-Sigma算法和控制图算法的优缺点

无监督学习算法的优缺点
有监督算法
告警收敛根源分析
参考
- 3、涂彦-AIOps仅仅是异常检测么
- avila--腾讯运维的AI实践v_0.4.pdf ★★★★★
- max--复杂业务的自动化运维精髓V2.pdf
360 AIOps ★★★★
时序序列算法
EWMA(指数加权移动平均)

另外还有各种同环比等算法介绍
机器学习架构
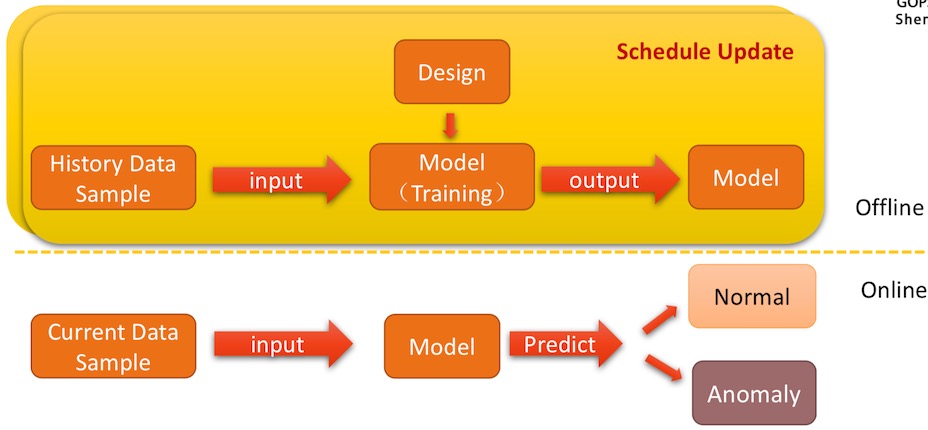
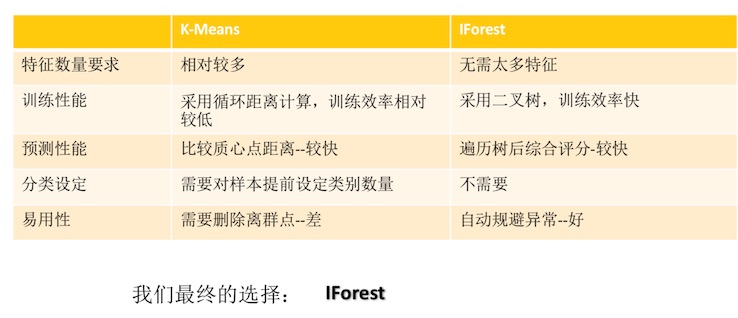
机器学习算法选择
参考
- 4、谭学士-360 AIOps 亮剑网络运维
华为AIOps实践 ★★★★
AIOps现实中面临的痛点、难点
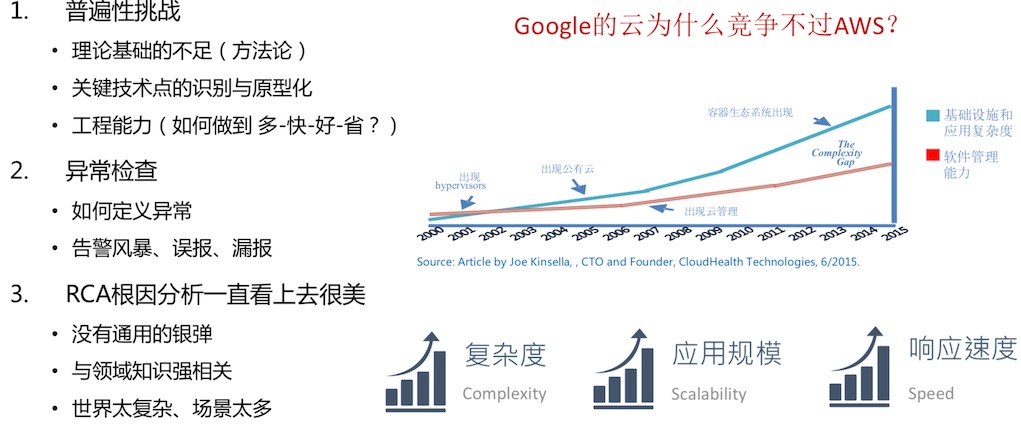
Serverless环境中因果序列追踪
需求:
对Serverless API调用依赖关系、异常检测、响应时间等的监控和分析
API的高频调用、临时性(使用时创建、空闲时销毁)等特性,调用链成为实
时监控的重要手段
函数trigger:提供日志事件触发函数调用的能力:1)能看到事件来源,便于跟 踪问题 2)供用户自定义功能扩展
多源数据的RCA分析探索
为什么说异常检测是AIOps的第一需求:
- 有异常才需要操作(Ops)
- 理解什么是正常pattern
单一时序变量
- 窗口法: sliding window, xxx window。手工配置大量参数(尤其是窗口大小),平衡延迟和误报率,即延迟短误报率会高,延迟长误报率低 。
- ARIMA、EWMA)等算法
多个时序变量预测单一事件
- Hidden Markov Model : 根据预设的事件依赖关系进行预测。 参数不多,计算量较小,每个节点 意义明确,但准确性非常依赖于预 设的Markov Chain
- Recurrent Neural Network, e.g. LSTM :隐变量意义不明确,参数较多,计 算复杂度较大,比较难收敛
聚类算法实现网络包的Blackbox分析
- Blackbox算法 :计算因果路径,即不同业务的服务间调用路径。
- 基于Hierarchical Clustering实现因果路径推导
参考
- 1、华为-华为三位一体探索 AIOps 关键技术的实践.pdf
原理部分
Holt-Winters模型原理
这两篇文章,由浅入深,从原理上指出了,Holt-Winters为什么可以解决残差、趋势、周期的问题。
Holt-Winters seasonal method ★★★
这篇文章介绍了原理,美团那篇文章中的公司参考的这里。同时,这里给出了仿真方式。
Holt-Winters原理和初始值的确定 ★★★
该文章介绍了参数的计算过程。同时给出来很多参考文献。
facebook prophet的探索(python语言)
介绍了时序型的分析框架。提供了Python和R两种语言支持。
- 可以研究下是否可以拿来使用。
- 吸收性该框架的思想,用到我们的设计中来。

