抽时间将数据驱动的一些内容进行了总结,先整理下面五篇,后续将不断完善。
整体概述
在本文中,我们采用整体到部分的分析思路。首先介绍大数据系统在整个公司架构中的位置,然后具体介绍大数据系统的架构实现,再次对大数据系统中的数据驱动部分进行分析,最后对数据驱动中的各个部分依次概述。 ## 整体架构 首先,我们需要确定大数据系统在一个公司整体架构中的位置。为了方便分析,我们引入云计算中的四个概念来设计整体架构,包括:IaaS、PaaS、SaaS、DaaS。不同于云计算中服务的概念,本文主要使用这4个概念对整体架构进行粗略划分。如下图,各层依次为:
- IaaS:意思是基础设施即服务。主要包括虚拟机、网络、负载均衡等一些基础设施。
- PaaS:意思是平台即服务。主要包括限流、通讯(RPC/http)、消息组件、注册中心、安全组件、文件系统等平台类软件。
- SaaS:意思是软件即服务。主要是公司的业务应用,具有很强的领域特性。
- DaaS:意思是数据即服务。可以简单的理解为,大数据系统是DaaS的一种实现形式。这里我们将其分为五层,由下往上依次为:采集层、计算层、存储层、驱动层、应用层。

大数据系统架构
架构分层设计
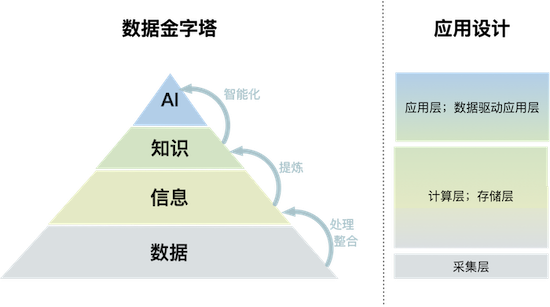
如下图,结合上篇文章介绍的数据金字塔理论,得到如下分层。
- 纵向分析:由下往上是一个逐步递进的关系,最上层数据量最小,但是为最有用的部分。大数据系统架构,主要从数据流的角度出发,将其分为:采集层、计算层、存储层、驱动层、应用层。
- 横向分析:如图所示,通过颜色将金字塔理论和架构分层映射起来,渐进色表示涉及到了多层。
- 采集层:对应金字塔理论的“数据”。
- 计算层和存储层:对应金字塔理论的“数据”、“信息”和“知识”。
- 应用层和数据驱动应用层:对应金字塔理论的“知识”和“AI”。
架构设计
如图所示,为大数据系统的架构图,主要分为采集层、计算层、存储层、驱动层、应用层5层。大数据系统根据采集的数据,使用实时计算和离线计算能力进行初步加工,然后,再利用规则、算法等能力赋能数据应用。
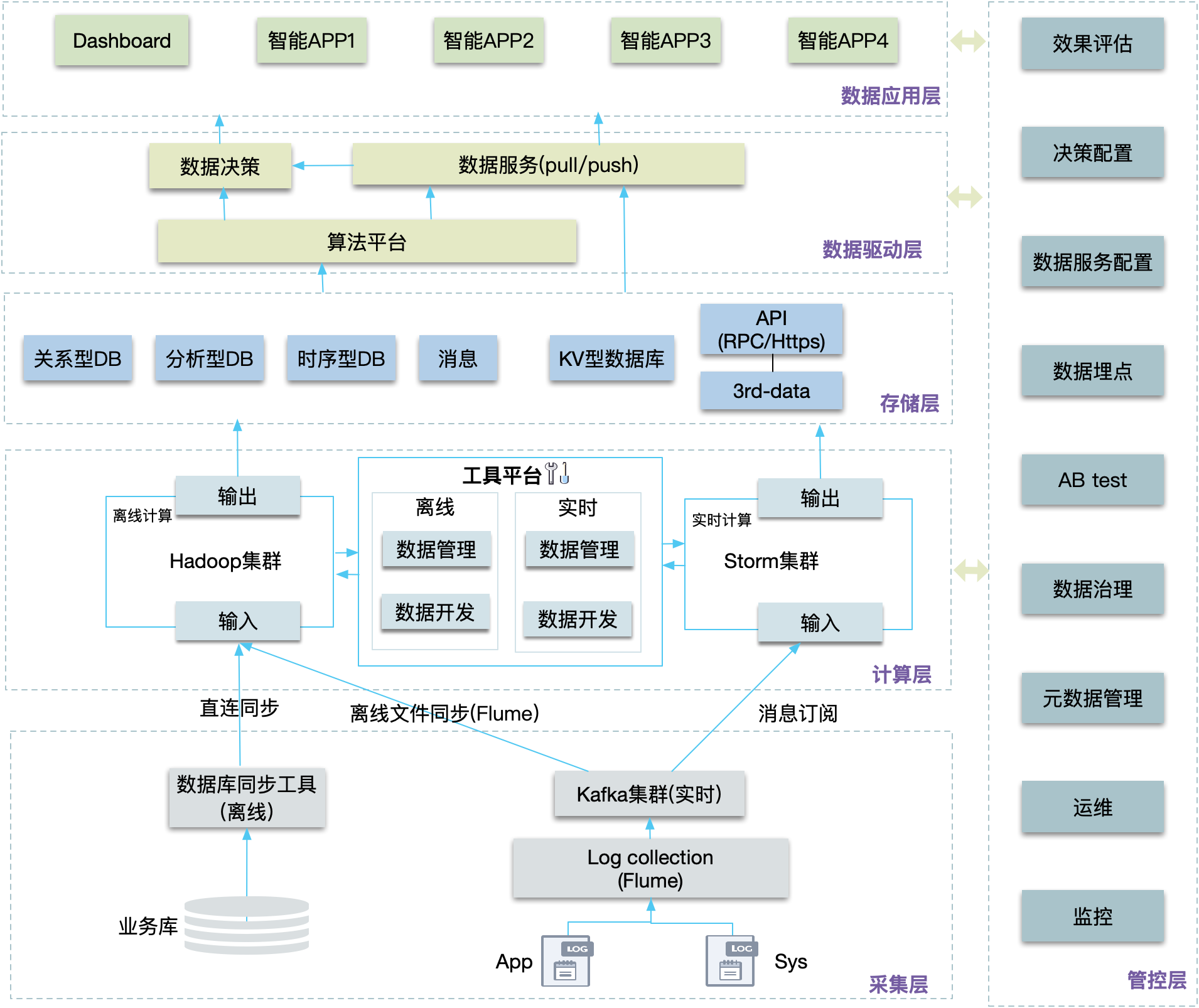
采集层
致力于全面、高性能、规范地完成海量数据的采集,并将其传输到计算层。被采集的数据种类包括:数据库数据和日志数据。
- 数据库数据:一般是采用T+1方式,离线同步到Hadoop。
- 日志数据:包括应用日志和系统日志,通过Flume采集日志,以Kafka消息的方式实时同步给Storm集群和Hadoop。
计算层
采集层得到的数据,将进入数据计算层中被进一步整合和计算。数据只有经过计算和整合,才能被用于洞察商业规律,挖掘潜在信息,从而实现大数据价值,达到赋能于商业和创造价值的目的。对于海量的数据,从数据计算频率来看,包括实时计算和离线计算两种方式。
- 实时计算:一般采用Storm、Spark等技术,提供秒级的计算能力。
- 离线计算:一般采用Hadoop技术。数据计算频率主要以天(还包括小时、周、月)为单位,比如T-1,则每天凌晨处理上一天的数据。接收kafka消息数据,计算的结果输出到存储层,或直接给驱动层。
工具平台提供数据管理、开发和整合的方法体系。用来构建统一、规范和可共享的全域数据体系,避免数据冗余和重复计算,规避数据烟囱和不一致性。
存储层
该层主要用来存储计算层加工后的数据。
- 关系型DB:用来存储业务数据和元数据。
- 分析型DB:用来存储报表、多维查询类数据。一般RT较高,为百ms级别,甚至s级。
- 时序型DB:用来存储状态数据、时间序列数据。
- 消息:以推的方式将数据传输到上层。
- KV数据库:实时计算的结果一般流出到Hbase,Hbase为分布式架构,方便扩容,从而做到容量大、QPS高、低RT。
- API(Dubbo/Https)提供一些业务系统数据,或者公司外部数据。注:业务相关的DB,通过dubbo接口查询。
- 缓存数据:通过分布式缓存对数据查询进行加速。
数据驱动层
该层主要是给数据应用层提供平台能力。包含3大部分:
- 数据服务:提供数据的查询和推送能力。
- 数据决策:提供数据的决策能力。
- AI算法平台:特征提取、模型选择、参数校验、模型训练。
应用层
基于数据服务、数据决策和AI算法这些基础能力,创建数据驱动型的应用。
管控层
提供数据的管理能力、监控能力、运维能力等,包括:配置管控、数据治理、元数据管理、血缘关系管理、监控、运维等。
数据驱动的架构
数据驱动的思想和架构对应关系
上篇文章讲到了数据驱动的思想,现在将其对应到架构中,则对应数据驱动层和数据应用层。如下图,感知器即为数据服务模块;决策器为数据决策模块和AI算法模块;执行器为数据应用层。
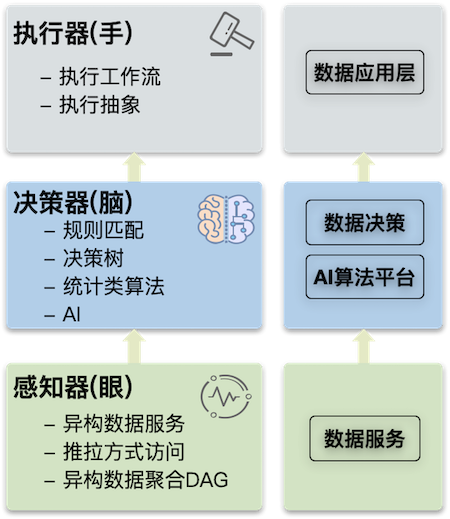
数据驱动的架构
下面对数据驱动的架构进行详细说明。下图是数据驱动的关键架构,也是我们要探讨的重点内容。
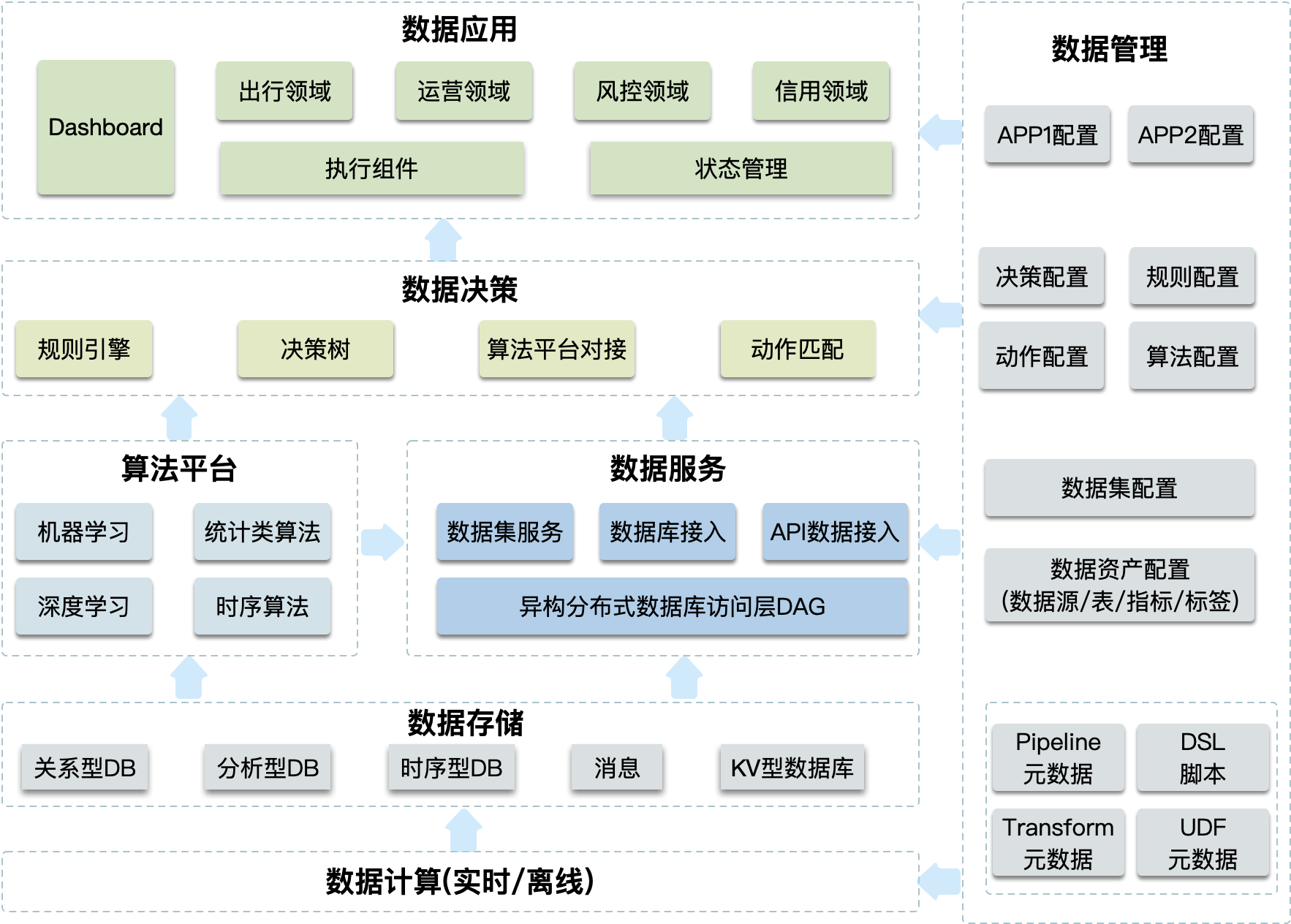
数据服务
通过接入数据存储层的各种数据源,基于异构分布式数据库访问层DAG,实现了对异构数据源进行处理和聚合,主要提供简单数据查询复合、复杂数据查询服务和数据实时推送服务。该模块主要将能力输出给数据引用层,好比将眼睛有选择地看到一些事物,然后传输给大脑。
AI算法平台
包括统计类算法、机器学习、深度学习、时间序列算法等。该模块接收存储层的数据进行离线训练得到所需算法模型,在对新数据进行预测。就好像大脑基于历史经历得到经验,经验即为模型。
数据决策
基于规则引擎、动作、决策树,提供决策能力。同时,也可以使用算法平台的算法能力进行决策。好比大脑根据经验,做出决策结果。
数据应用层
对于多类数据应用,抽象出执行组件和状态管理两部分。基于这两类组件,可以构建出行领域、运营领域、风控领域、信用领域等应用。该层使用了数据驱动层的平台能力,可以方便的创建各类数据应用,让数据快速、方便、有效地发挥价值。该层负责将眼睛看到的新数据传输给大脑,得到大脑的决策结果后,再用手去执行。
数据管理
对计算层、数据服务、数据决策、AI算法平台、数据应用层的配置进行管控。计算层包括Pipline、DSL、Transform、UDF等元数据;数据服务包括数据集配置和数据资产管理;算法平台包含算法相关配置;决策模块包括决策配置、规则配置、动作配置和算法配置;应用层包括各个应用的配置。
小结
本文重点讲述了数据驱动的架构。在后面的文章中会依次介绍数据服务、数据决策、算法3部分的详细架构实现。对于数据采集层、数据计算层和数据存储层成熟方案已有很多,非本系列文章重点。
参考
- 大数据之路——阿里巴巴大数据实践
- 数据即服务(Data as a Service; DaaS)
- 云计算四层分——IaaS、PaaS、SaaS、DaaS

