抽时间将数据驱动的一些内容进行了总结,先整理下面五篇,后续将不断完善。
概述
主要概念
- 数据服务(Data Service):对异构数据源,基于有向无环图,提供异构数据的查询和推送能力。
- 指标:用于衡量事物发展程度的单位或方法,它还有个IT上常用的名字,也就是度量。例如:人口数、GDP、收入、用户数、利润率、留存率、覆盖率等。
- 维度:是事物或现象的某种特征,如性别、地区、时间等都是维度。一般指查询约束条件。
- 粒度:维度的一个组合。描述分析需要细分的程度。
- 数据集:用来描述数据从哪里来,有哪些字段输出,提供哪些能力(过滤、分组),数据表的Join关系,粒度等等
- HTAP数据库:Gartner提出了HTAP数据库概念,一个数据库既能支持OLTP(在线事务处理),又能支持OLAP(在线分析处理),涵盖大部分企业级应用的需求,一站解决这些问题。
异构数据查询产品对比和分析
本文的主要目的是设计一个轻量级的异构数据查询和推送系统。首先,先看下主流的异构数据查询系统,如下表格:
| Presto | F1:Query | Calcite | TiDB | |
|---|---|---|---|---|
| 描述 | 分布式大数据查询引擎(SQL) | 大数据异构查询引擎 | 动态数据管理框架 | 分布式 HTAP数据库 |
| interactive交互式查询 | 提供 | 提供:集中式查询、分散式、批量查询ETL | 支持 | 支持 |
| 数据源类型 | 多种 | 多种 | 多种 | 多种 |
| 支持自定义数据源 | 支持 | |||
| 使用公司 | ||||
| 代码开源 | 是 | 否 | 是 | 是 |
| 异构聚合 | 是 | 是 | 是 | |
| 模式 | Coordinator-Worker | Master-Server-Worker | ||
| 存储数据 | 否 | 否 | 否 | 是 |
| 分布式 | 是 | 是 | 是 | |
| ACID事务特性 | 分布式事务 | |||
| UDF | UDF server | |||
| 水平弹性扩展 | 支持 | 支持 | ||
| HTAP(OLAP/OLTP) | 支持 | 支持 | ||
| 特性 | 批量化 + 异步化 + 流水线化DAG |
空白部分,表示没有找到相关说明。
本文的目标
本文设计的数据服务,基于有向无环图DAG,对异构数据源进行处理和聚合,主要提供简单数据查询复合、复杂数据查询服务和数据实时推送服务。 优势
- 轻量级的异构数据查询引擎
- 结构化语义,无SQL
- 融合数据管理
- 支持异步消息的推送
- 面向智能应用
存在的缺点
- 不支持离线批处理
- 不支持分布式计算
- 只支持大量数据的异构join和聚合
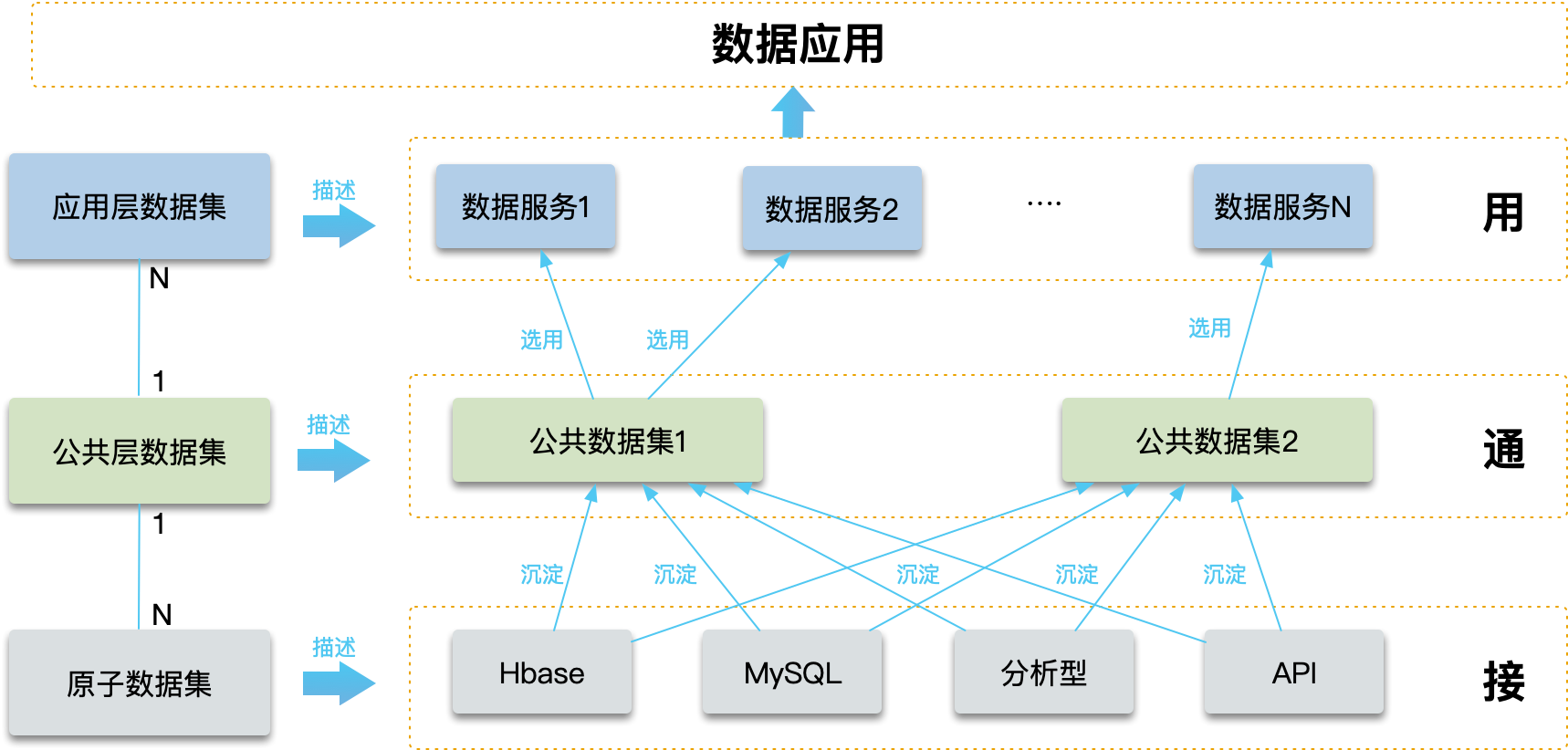
三层数据集思想
根据功能和层次的不同,将数据集分为3类,由下向上依次为原子数据集、公共层数据集、应用层数据集,如下图所示。
- 原子数据集:原子数据集是一层逻辑上面的概念,用来接入数据源,包括各种数据源的数据,如HBASE/MySQL/API等。
- 公共层数据集:多个原子数据集沉淀之后,形成公共层数据集;当然,一个原子数据集也可以被多个公共数据集使用。前期,该层也是一个逻辑概念,需要随着时间慢慢积累;用来管理不同业务的数据,原则上同一个业务可以抽象为几个公共数据集。公共层主要起到 了管理作用,并确定统一的数据口径。
- 应用层数据集:一个公共数据集可以产生多个应用数据集,面向智能应用,直接赋能给应用。
领域模型
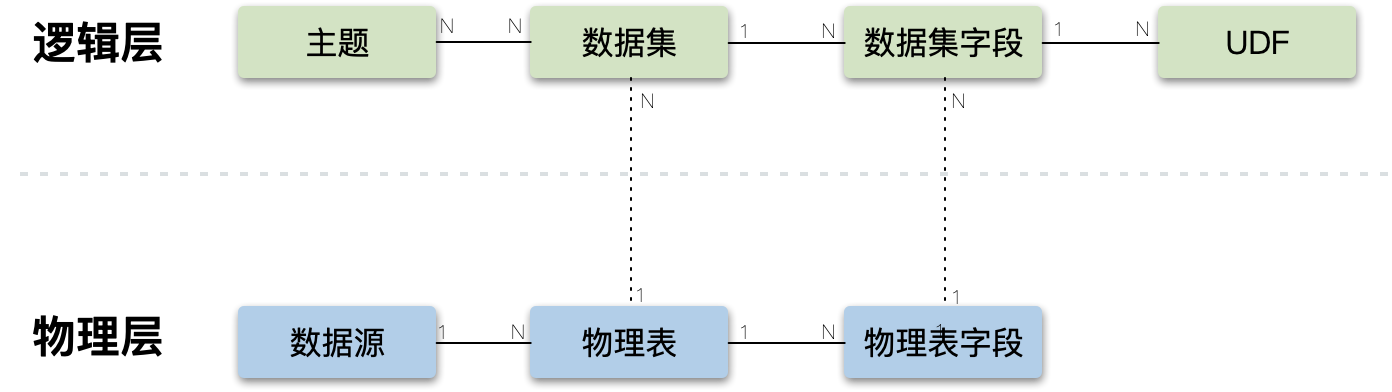
如下图,领域模型分为逻辑层和物理层。
- 物理层:数据源主要是各种数据的来源,包括MySQL、HBASE、kafka等。数据源里面的表抽象为物理表,表中包含物理字段,物理字段主要有维度、指标和标签3种类型。
- 逻辑层:数据集是对物理表的逻辑抽象,一个数据集可能来自不同数据源的多个物理表,其字段称为数据集字段。对数据集字段包装的时候,可以使用自定义的Transform和UDF。通过主题来管理数据集,一个主题包含多个数据集,一个数据集也可以属于多个主题。
技术架构

- 元数据管理:主要提供数据集、物理表、标签、指标等元数据能力。
- Meta Data Local Cache: 提供元数据的本地缓存。元数据使用定时刷新机制。
- 数据安全:主要是SQL注入等安全问题。
- 数据权限:主要是权限的控制,分为数据集维度和字段维度的权限控制。
- Query Parser:查询条件的解析,以及元数据的解析。一般减少每次解析的工作量,需要缓存解析后的元数据。
- Query Plan Builder (构建执行计划):主要是根据查询条件和元数据信息,构建有向无环图DAG。这里是本系统的难点。
- Optimizer (执行计划的优化):根据查询条件和元数据信息,对执行计划进行优化。
- Scheduler (调度):根据构件好的DAG,调度相应的执行器Executor执行。
- Executor (执行器):这里的执行,多线程并发执行。
- Runner:主要是各种数据源的适配和性能优化,是一个原子的取数逻辑。主要是实时返回数据的数据库,不支持ETL离线型数据源。
- Merger (合并):主要是数据的合并,可以抽象为
left join和full join两种类型。 - Assemble (包装):对字段进行包装,对行列数据进行转换。同时,可以自定义用户函数。这里会用到标签和指标元数据等信息。包装后的结果,将直接输出。
注:OLTP和OLAP两类查询是隔离的,OLTP为快查询,OLAP为慢查询,因为OLAP一般耗时会到1s左右,可能影响OLTP的性能。
系统整体设计
数据集设计
根据查询粒度的不同,将查询分为三类:多为统计查询、主键查询和非主键多条件查询。其中,主键查询和非主键多条件查询为单维查询,主键查询的维度就是主键。
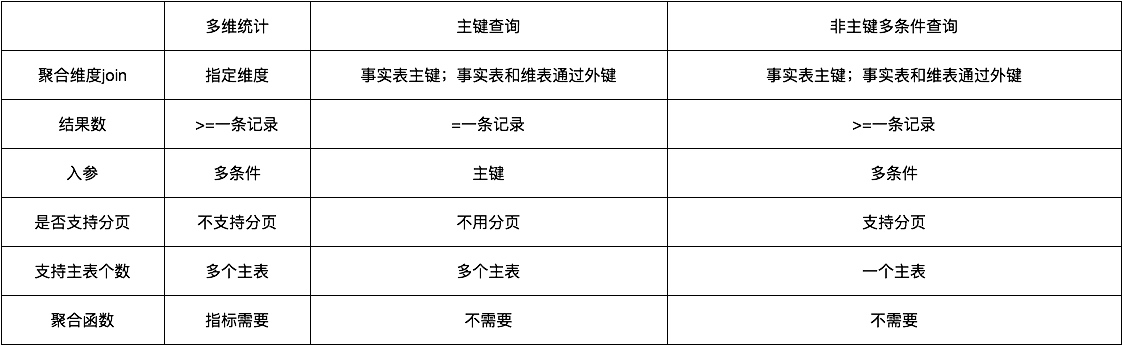
1.多维统计
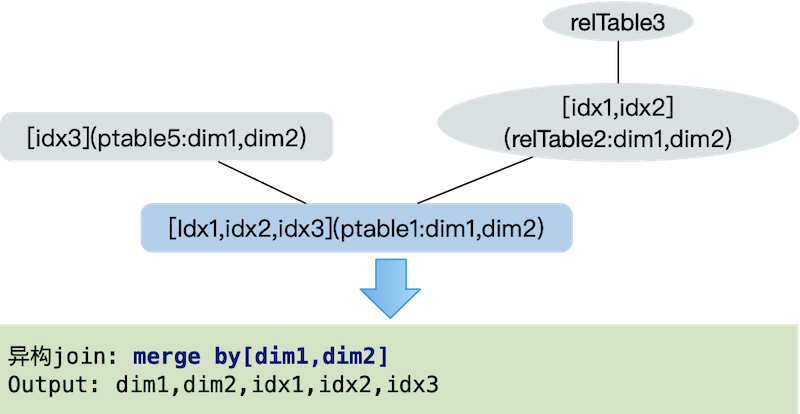
多维统计是由"维度+指标"组成的聚合类数据,即聚合字段(group by)+过滤字段(where)+筛选字段(select)。数据集中的粒度(grain)决定了需要输出的维度组合,聚合维度(group by)字段属于粒度的子集,查询条件中的维度字段属于聚合维度的子集。多维统计由多个异构主表(事实表)内存Join,分别查完后按同粒度Grain进行join后输出。如下图所示,两个事实表包含相同的维度,不同的指标,经过内存join后,输出所需指标和维度。

2.单维详情查询——按主键PK查询
通过主键(PK)查询主表一条记录,通过主表的外键查连接其他表(一般是维表)的数据,并且可以支持多级连接,支持多个主表查询。通过主键,在内存进行merge join,输出结果一般为单条记录。

3. 单维详情查询——非主键查询
通过非主键的各种条件,查询一批主表记录。该查询中需要有一个确定的主表,通过主表来对结果进行分页查询;其他的表均为关联表,通过主表的外键连接多个关联表。
参考:
系统详细设计
系统流程
如下图,描述了整个系统的设计流程上的关键部分,同时,对各部分的关键点和设计模式进行了说明。
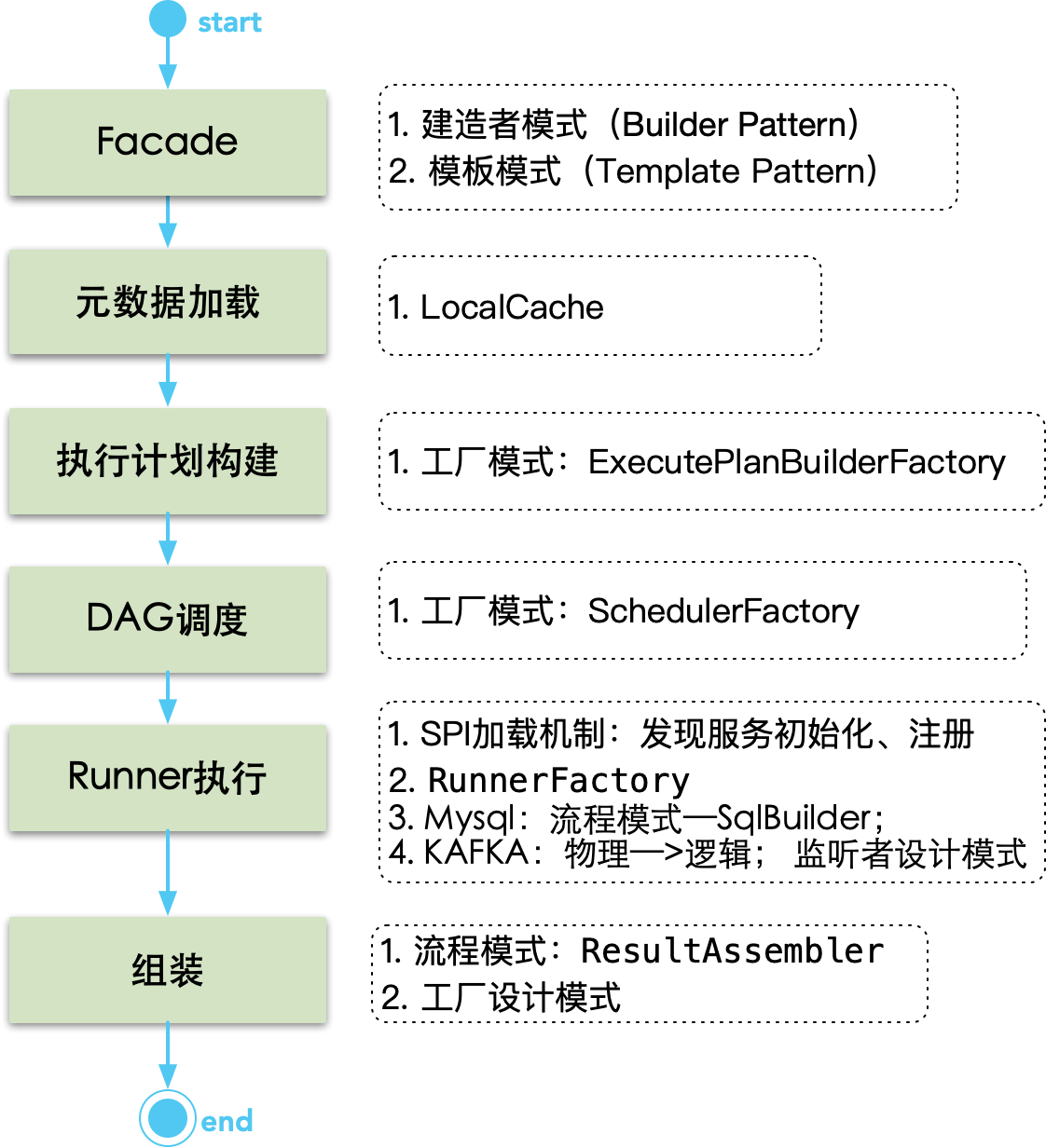
元数据加载
该部分主要做了:入参解析、元数据解析、元数据缓存。
入参解析:将用户的查询解析为系统参数,主要包含3种解析类型:
GroupByQuery/PkQuery/NormalQuery元数据解析:将数据库非结构元数据解析为结构对象,减少每次结构化的成本。同时,将查询入参和结构化元数据进行合并,得到一个内部对象。
元数据缓存:缓存采用定时刷新机制。根据数据集name加载数据集配置信息,包含:数据集、数据集字段、用到的物理表和用到物理表的字段。
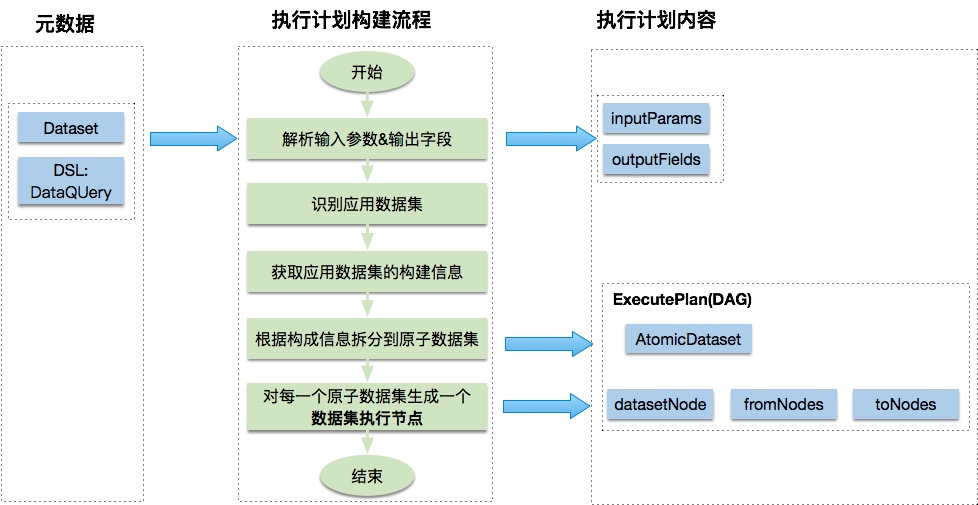
执行计划构建
执行计划构建就是根据请求参数和元数据,生成数据查询的执行计划。构建的查询计划是一个有向无环图DAG(Directed Acyclic Graph),每个节点是一个原子数据集。执行计划生成逻辑如下图,左边为加载的元数据信息,中间为执行计划构建流程,右边为执行计划的内容。
执行计划调度
执行计划调度是指,根据前面构建的执行计划DAG,分配线程、调用Runner执行查询,再合并结果。
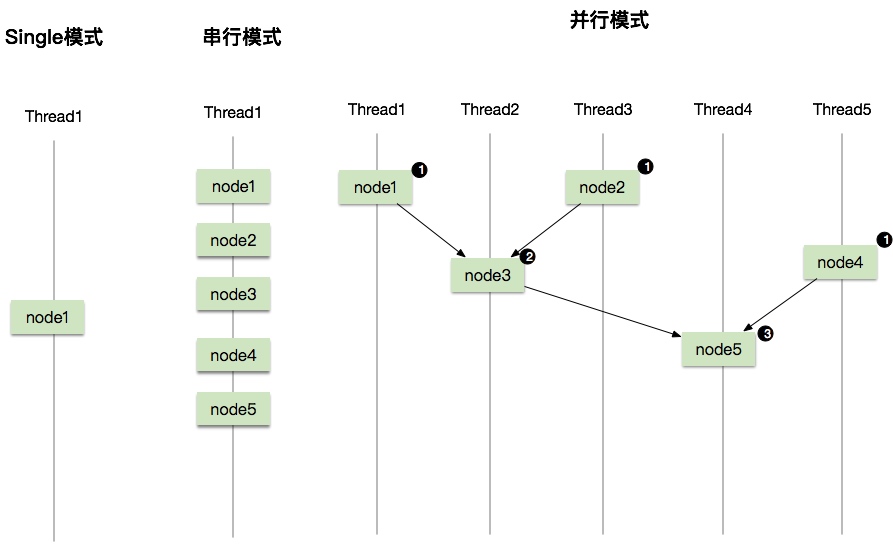
执行模式
DAG的执行过程,就是执行各个子节点(原子数据集)的过程。根据每次执行节点数的不同,分为三种执行模式:Single模式,串行模式、并行模式。如图,每个阶段均为一次原子执行,同时节点中还可能包含合并merge操作。
- single模式:一次只支持一种原子查询。
- 串行模式:支持多次原子查询及合并。在同一个线程中串行执行,有多少个节点就串行执行多少次。
- 并行模式:支持多次原子查询及合并。在多个线程中并行执行。根据DAG层数进行调度,即DAG有多少层,就并发执行多少次。执行过程中,每次执行入度为零的所有节点。如图所示,第一次执行
node1/node2/node4,第二次执行node3,第三次执行node5。
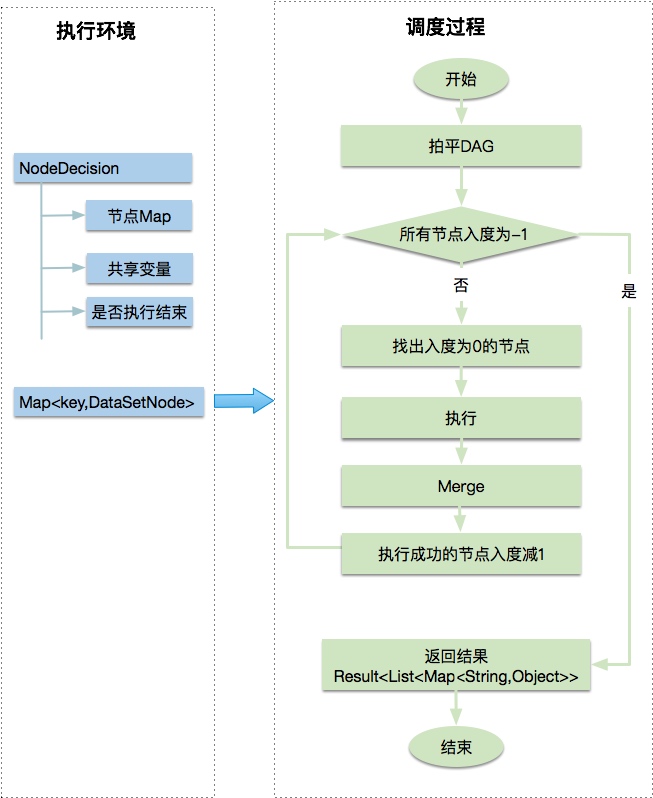
调度执行过程
如下图,左侧为执行环境(元数据),右侧为调度过程。首先将DAG拍平,每次找出入度为零的节点执行、合并结果,执行完该节点后,对被引用的节点入度减一。递归执行,直到所有节点入度为-1。
Runner执行
类似于jdbc模块的方案,本文使用SPI(Service Provider Interface)机制发现服务,从而实现模块的解耦。同时,如果需要在外部开发定制Runner,使用SPI机制可以更好地实现。Runner种类包括MySQL、HBASE、kafka、dubbo等。下面主要介绍一种实现,即SQL类Runner:SqlRunner
SqlRunner
如下图所示,SqlRunner主要作用是将结构化的对象解析为数据库可执行的SQL。解析工具包括:FilterBuilder、JoinBulider、GroupByBulider、SortBuilder、PageBuilder。

FilterBuilder
- 根据Filter构造Where子句。需要对"=”、"in”、"range”、"like"四种类型的Filte进行解析。其中,range条件已经被上层区分为“>”、“>=”、“<”、“<=”,可以与"="、"like”共同视为单一条件值条件,组装为“字段操作符条件值”,其中条件值要根据类型决定是否加单引号。
- 特殊类型字段(如时间) 需要根据底层DB的标准进行翻译。
JoinBulider
构造Join子句,包括left join和full join。
GroupByBulider
根据grain字段构造group by子句,聚合列以grain为准。
SortBuilder
取OrderBy对象中的字段名和升降序类型拼接ORDER BY子句。
PageBuilder
取原子数据集上面的pageSize和pageNum字段。如果~,则无偏移;否则用(pageNum-1)*pageSize计算偏移,拼接LIMIT子句。
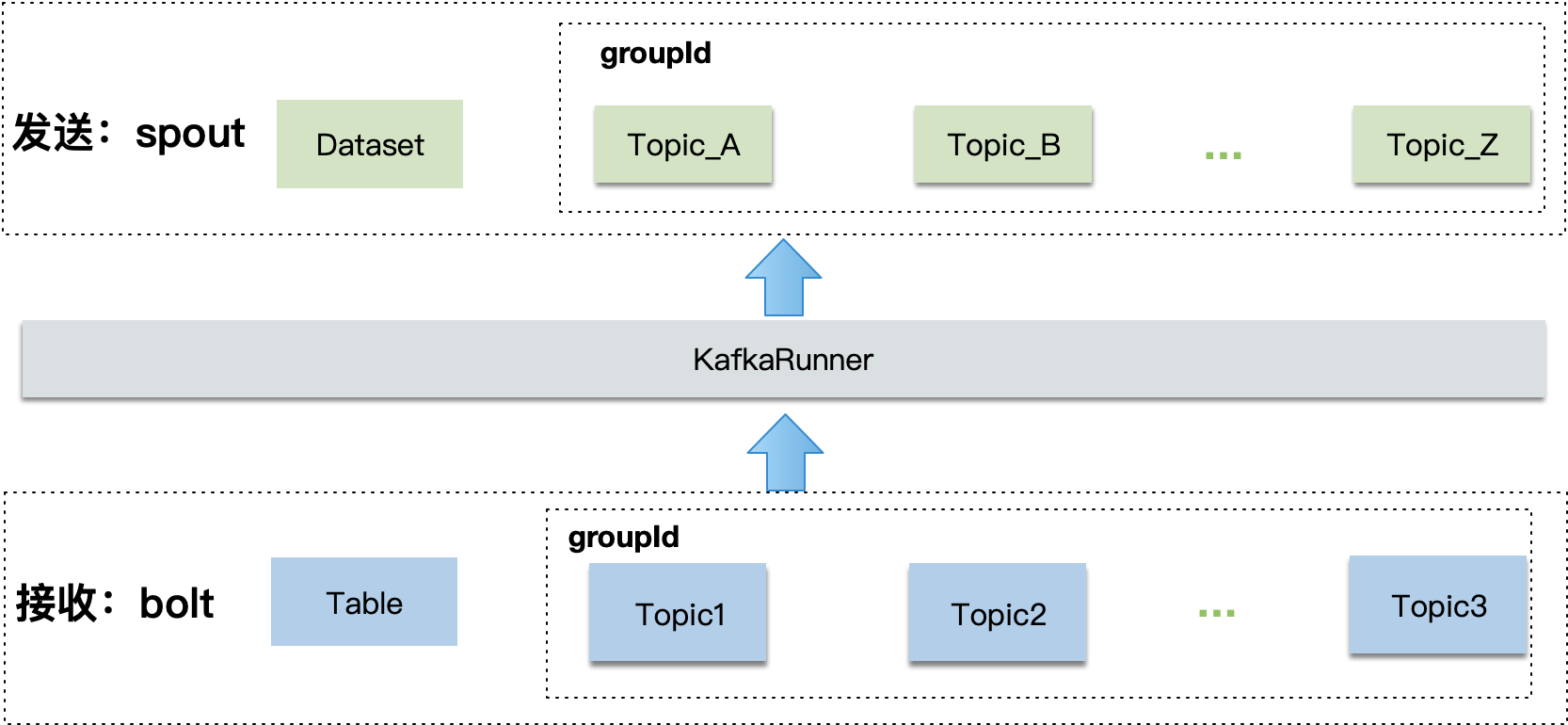
Kafka-Runner
系统监听指定的Topic消息,收到消息后进行处理,并以异步消息的方式再把消息发送出去。其中,发送出去的消息中,携带其他异构Runner的数据信息。
执行流程
如下图所示,接收到消息后,通过KafkaRunner处理后,再将消息发送出去。
- 接收端:
- 接收不同的topic,接收的topic对应于领域模型的
Table。使用同一个groupId,每个消息只接收一次。 - 将入参解析为KV的map,本期只解析一层,后续有需求再支持解析多层。
- 异步数据集,只能通过消息来触发。
- 一个数据集只支持引用一个Topic。(引用多个Topic,会导致消息等待的问题,暂时不考虑支持这种复杂场景。)
- 接收不同的topic,接收的topic对应于领域模型的
- 发送端:
- 将经过处理后的数据,以消息形式发送出去。对应领域模型的数据集
Dataset。
- 将经过处理后的数据,以消息形式发送出去。对应领域模型的数据集
运行时更新Topic
对于Kafka,一张物理表对应一个Topic。动态新增一张表的时候,需要在运行时,定时更新其对应的Topic。其中的关键点在于,更新Topic要保证在元数据加载完成之后,否则,可能导致接收到的消息数据,无法消费发送出去。kafka对自动新增和删除topic支持不是很好,需要自己实现一些内容。具体可以参考下面链接。
参考:
- how can i set consumer's topic by code
- https://github.com/spring-projects/spring-kafka/issues/213
数据组装
组装器是对字段或者行列的处理,包含包装、转换、排序、内存分页。
- 包装:针对单字段的处理。
- 类型转换包装
- 展示数据包装
- 可视化参数包装
- 字段跳转URL包装
- 转换:行列转换、多行转单行等。
- 排序:主要是对异构合并的数据进行排序。优先使用Runner自身的分类器。
- 分页:对异构合并的数据进行分页返回。总条目数不宜过多。
总体原则:优先使用底层的能力,比如要分页的时候,如果Runner底层不能满足的时候,才使用上层的Pager。或者要进行数据合并时,优先使用数据库自身的join,不能满足时再考虑内存Merger。
小结
本文主要介绍了一个轻量级的异构数据查询和推送系统。由于内容较多,本设计的很多细节没有深入介绍。

