抽时间将数据驱动的一些内容进行了总结,先整理下面五篇,后续将不断完善。
概述
决策引擎主要目标是将业务决策逻辑从系统逻辑中抽离出来,使两种逻辑可以独立于彼此而变化,这样可以明显降低两种逻辑的维护成本。下面列举三种方案,然后分析各自优缺点,从而确定本文的方案。
方案一:硬编码实现方式
优点:
- 当规则较少、变动不频繁时,开发效率最高。
- 稳定性较佳,语法级别错误不会出现,由编译系统保证。
缺点:
- 规则迭代成本高,对规则的少量改动就需要走全流程(开发、测试、部署)。
- 当存量规则较多时,可维护性差。
- 规则开发和维护门槛高,规则对业务分析人员不可见。业务分析人员有规则变更需求后无法自助完成开发,需要由开发人员介入开发。
方案二:开源方案Drools
配置流程
使用 Drools 的规则配置流程如下图。一般只适合开发人员使用。
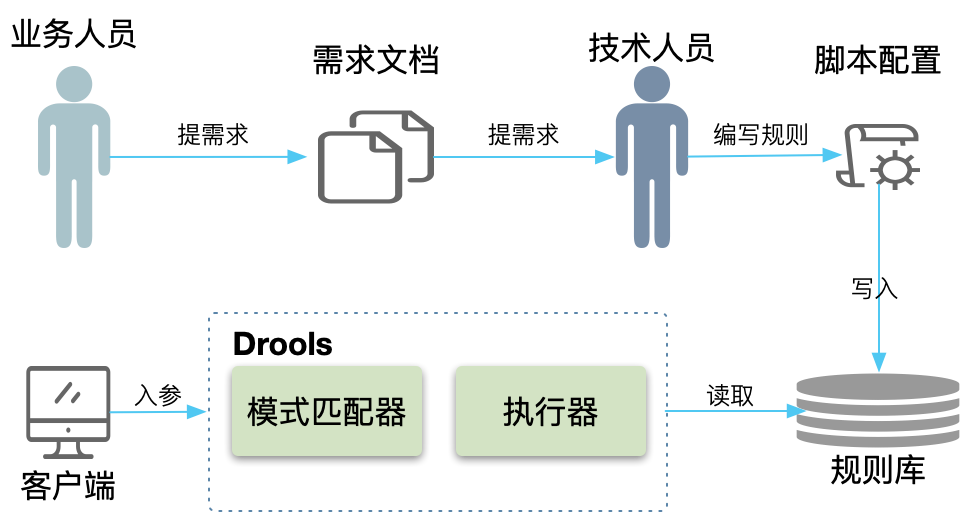
优点:
- 策略规则和执行逻辑解耦方便维护。
缺点:
- 业务分析师无法独立完成规则配置,由于规则主体 DSL 是编程语言(支持 Java,Groovy,Python),因此仍然需要开发工程师维护。
- 规则规模变大以后也会变得不好维护,相对硬编码的优势便不复存在。
- 规则的语法仅适合扁平的规则,对于嵌套条件语义(then 里嵌套 when...then 子句)的规则只能将条件进行笛卡尔积组合以后进行配置,不利于维护。
方案三:设计轻量级决策引擎
针对硬编码和drools方案的不足,我们开发了一套适用于运营、产品、业务、开发等人员的决策引擎。
下图是配置系统,业务人员配置决策、决策树和决策列表,开发人员负责配置底层更原子的一些组件:规则、动作和因子。随着平台积累和完善,逐渐也将规则、动作和因子交给业务人员去配置。配置后的决策元数据落地到决策库。决策引擎从决策库获取元数据,依次经过获取因子数据-->规则解析-->决策执行,将结果输出到数据应用层。
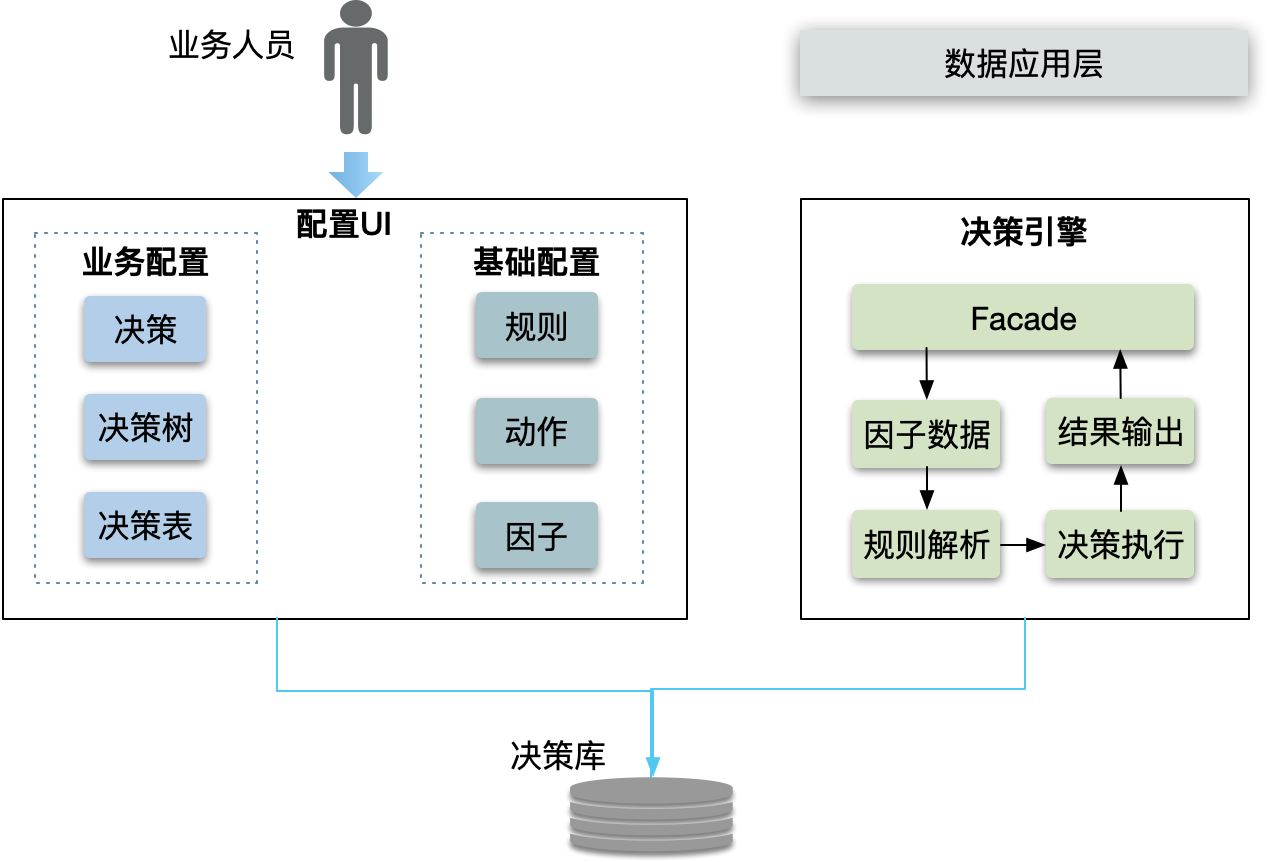
优点:
- 规则配置门槛低,因此业务分析师很容易上手。
- 系统支持规则热部署。
- 业务和规则解耦,可以推广到别的业务。
小结
通过三种方案的分析,总结如下:
- 硬编码迭代成本高。
- Drools 维护门槛高。视图对非技术人员不友好,即使对于技术人员来说维护成本也不比硬编码低。
- 自开发决策引擎,配置门楷低,可以方便推广到其他业务。同时,后期还可以扩展更多能力:灰度、试跑、效果评估等。
因此,我们自开发一套数据决策引擎。主要功能包括:
基础决策能力:包含单个决策、决策树和决策表。
AI决策:部署训练后的模型,提供基于AI算法的决策。
领域模型
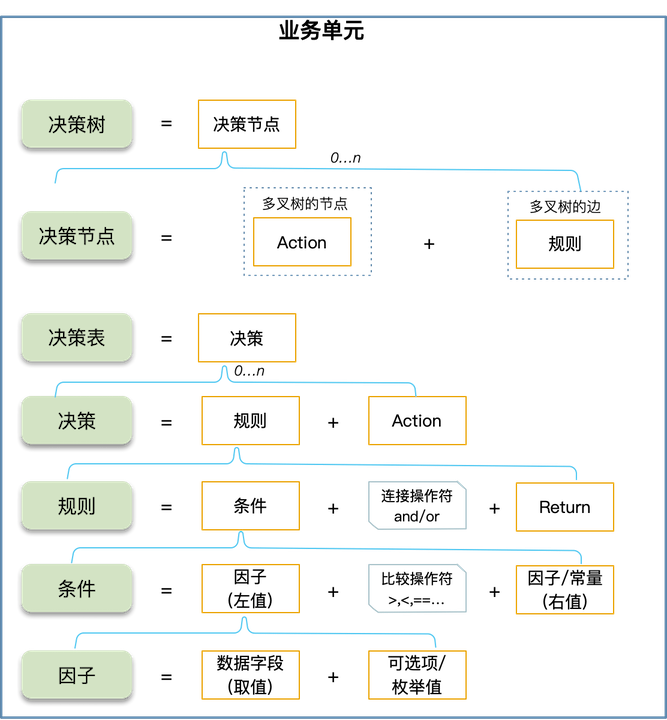
领域模型,由下往上依次为:
- 决策的最小元素是因子,因子由数据字段的取值和可选项组成,可选项主要用作配置过程中,方便非开发人员选择可选的值。
- 条件由因子和操作符组成,操作符包括:加、减、乘、除、包含、不包含等。
- 规则由多个条件,通过连接符
and/or组成。本质上,规则就是一些条件,通过语法树组合而成。 - 决策输出的3种模式:
- 决策:决策时对外输出的最小方式,由规则和Action组成。
- 决策树:本质上是一颗多叉树,每个节点由规则和Action组成。根节点没有规则和Action,叶子节点必有规则和Action,中间节点必有规则(Action可选)。
- 决策表:多个决策组成决策表。
- 业务单元:用来做业务隔离,类似于类目管理的作用。不同业务单元之间的因子、规则模板和动作模板,都是相互隔离的。一般来讲,业务单元都是比较大的概念,整个公司不会有太多业务单元。
技术架构

架构主要流程:
- 最底层为数据层,HBASE主要存放一些实时计算的结果;MySQL为业务数据;API为http/https/dubbo接口数据,异步消息主要是Kafka数据。
- 算法平台使用数据层的数据,进行模型训练,再通过实时打分模块输出结果。结果输出给数据服务,或者直接输出到数据决策。
- 数据服务将数据层和算法的结果输出给数据决策。
- 数据决策模块,基于规则和算法模型,进行评分或者匹配,同时可以对结果进行排序。将决策的结果和动作,通过dubbo服务提供出去。
- 数据应用层使用数据决策和数据服务的能力,完成自己的功能。
- 通过埋点数据,进行决策效果评估和监控,评估的结果可以反馈给算法平台和管控平台。
- 管控平台,主要配置规则、因子、Action,进行灰度发布,规则试跑,多版本管理等。
数据决策的主要流程:
- 元数据加载:
- 缓存:引擎运行过程中,需要使用缓存技术降低远程通信开销。
- 预解析:缓存解析后的规则,而不是原始规则。从而,减小解析开销。
- 因子数据获取:获取决策所需要的实例数据,直接使用数据服务DS的输出。
- 执行:基于表达式解析引擎MVEL(表达式引擎性能对比,详见参考文档),提供决策、决策树、决策表3种决策能力。
- 决策:多个规则和一个Action。
- 决策表:N * (多个规则+1个Action)。注:决策表种的每个决策都有自己的优先级,默认值为100。
- 决策树:通过深度优先遍历或者广度优先遍历,根据节点优先级,执行每个决策点。注:每个决策点,都有自己的优先级,默认值为100。
- 执行策略:针对决策树和决策表,两种模式:
ONCE:只将匹配的第一个叶子节点的结果返回。ALL:将匹配到的所有叶子节点都返回。
- 结果拼装:
- 执行路径拼装:主要针对决策树和决策列表,将执行路径返回。
- 匹配Action:将所有匹配到的Action返回,同时返回其优先级。
- Rank:主要是针对批量决策,将匹配到的结果进行排序,并返回。
- Facade:将拼装的结果通过统一接口返回。
系统实现
Facade接口
提供两种类型的决策:单个决策和批量决策。批量决策主要是为了减少多次接口调用的消耗。
语法树抽象
缓存
缓存的主键key为业务单元-决策类型-决策code。如下图:

缓存数据前需要对元数据进行预解析,从而决策引擎可以执行预解析后的数据。需要预解析的部分:
- 将模型转换为表达式引擎可执行的形式。
- 决策树:先遍历,将遍历的结果缓存。而不是每次都遍历执行树。
决策执行
将执行过程抽象为两部分:决策执行层和公共执行层。
- 决策执行层:实现了决策、决策树和决策表的执行逻辑。
- 公共执行层:为决策执行层提供公共的执行组件,包括动作执行器和规则执行器。
决策执行层
决策树执行器
加载元数据后,利用深度优先遍历的方式执行决策树,本质是一个递归的过程。执行方式有两种:ONCE,即执行的过程匹配到一个叶子节点后,停止执行;ALL,即要执行玩所有分支,才停止。执行结束后,对结果进行封装,并返回。决策树的节点,分为3种类型:根节点、中间节点和叶子节点。各节点和Rule、Action的关系如下表:
| Rule | Action | |
|---|---|---|
| 根节点 | 无 | 无 |
| 中间节点 | 有 | 无 |
| 叶子节点 | 可选 | 有 |
决策执行器
决策执行器是决策树执行器的一种特殊形式,即:一个只包含Action和Rule的节点。
决策表执行器
决策表执行器是决策执行器的List形式,也包含ONCE和ALL两种执行模式。
公共执行层
规则执行器
规则执行器的作用是,根据表达式和参数得到执行结果。底层采用成熟的表达式引擎来实现。为了方便扩展,使用工厂设计模式,可以方便地切换到不同的表达式引擎。各表达式引擎对比详见详见 表达式引擎性能比较。经过比对发现使用Mvel预编译,且指定输入值类型的方式效率最高,故采用该方式。该方式没有缓存,因此自己实现一层缓存,来缓存预编译的结果。同时,采用2小时无访问,则失效缓存的策略;从而防止堆积过多无用规则配置。
动作执行器
根据入参、规则结果和上下文,执行响应操作,得到结果code。Action的执行类型有多种,用户可以自己定制。下面说两种执行器:
- 返回固定内容:匹配到规则后,直接返回配置的内容。
- 返回动态内容:根据入参和规则结果,对其进行处理,然后返回动态内容。
小结
本文实现一个轻量级的决策引擎,本方案具有以下特点:
- 规则表达能力强:通过决策、决策列表和决策树3种模式,可以覆盖多数的规则需求。
- 接入成本低:统一的页面配置,统一的接口接入。
- 规则运行/切换效率高:引擎运行过程中,需要使用缓存技术降低远程通信开销。同时,需要缓存解析后的规则,而不是原始规则。
- 两种运行模式:执行模式和调试模式。
- 易用性:方便配置,面向业务人员。
- 易管理:通过因子、规则、动作等领域模型的抽象,更方便元数据的管理。通过业务单元进行业务隔离,从而既具有隔离性又具有复用性。
- 规则迭代安全:规则支持热部署:系统通过版本控制,可以灰度一部分流量,增加上线信心。
当然本方案还有一些不足,比如没有实现复杂的决策场景,如动态规划、决策树剪枝等;没有实现复杂的规则能力。

