Apache flume
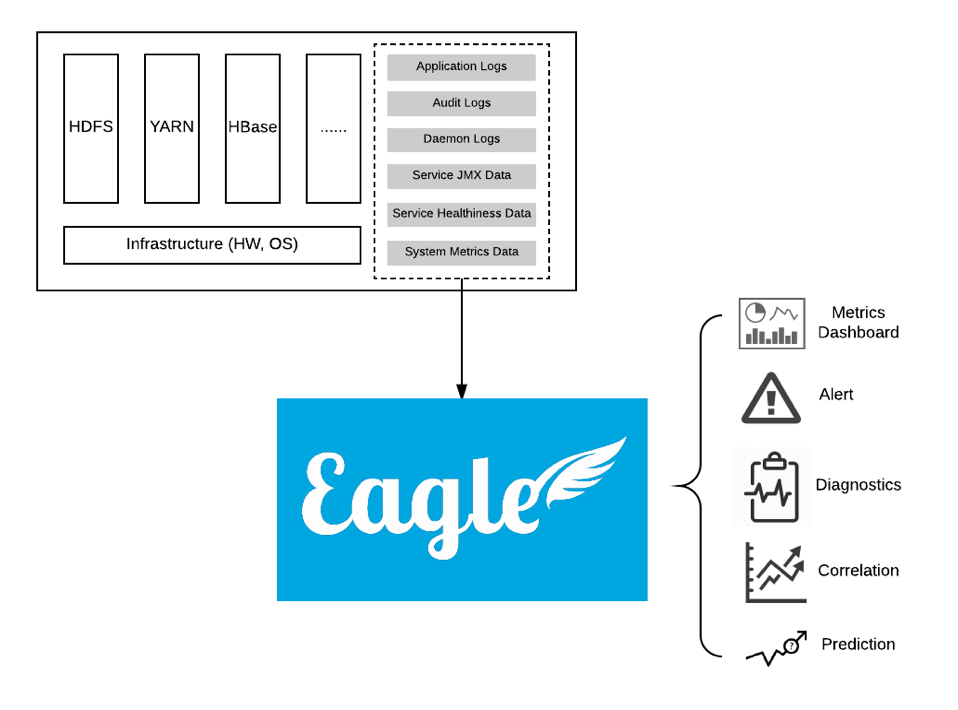
flume是分布式的日志收集系统,它将各个服务器中的数据收集起来并送到指定的地方去,比如说送到图中的HDFS,简单来说flume就是收集日志的。 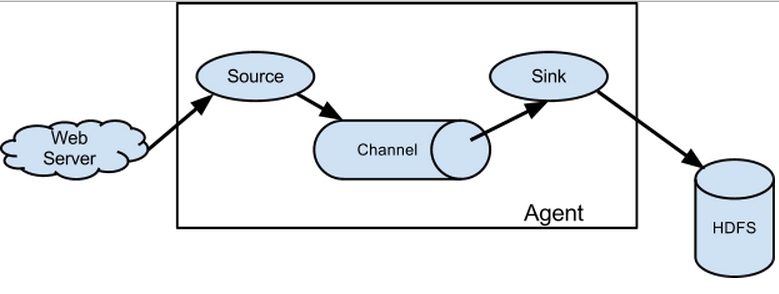 ## 同类产品对比 Flume使用基于事务的数据传递方式来保证事件传递的可靠性。而logstash内部是没有persist queue,所以在异常情况下,是可能出现数据丢失的问题的。
## 同类产品对比 Flume使用基于事务的数据传递方式来保证事件传递的可靠性。而logstash内部是没有persist queue,所以在异常情况下,是可能出现数据丢失的问题的。
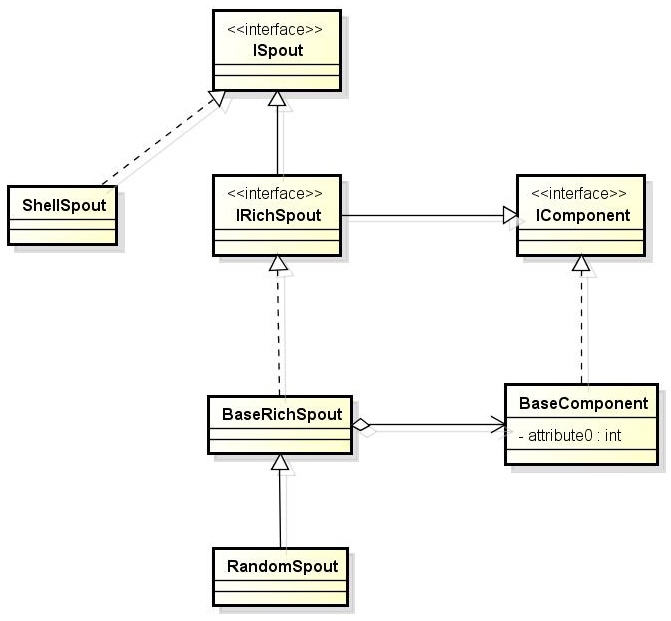
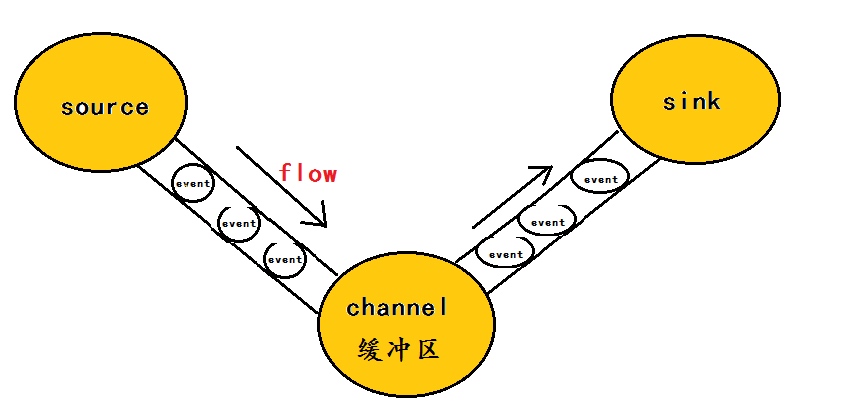
具体可参考下面的文档。 ## event event将传输的数据进行封装,是flume传输数据的基本单位,如果是文本文件,通常是一行记录,event也是事务的基本单位。flume的核心是把数据从数据源(source)收集过来,在将收集到的数据送到指定的目的地(sink)。为了保证输送的过程一定成功,在送到目的地(sink)之前,会先缓存数据(channel),待数据真正到达目的地(sink)后,flume在删除自己缓存的数据。
flume架构介绍
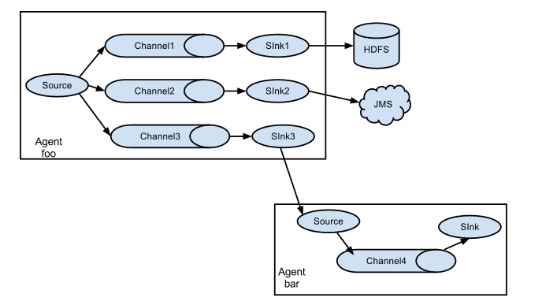
- agent:本身是一个java进程,运行在日志收集节点—所谓日志收集节点就是服务器节点。 agent里面包含3个核心的组件:source—->channel—–>sink,类似生产者、仓库、消费者的架构。
- source:source组件是专门用来收集数据的,可以处理各种类型、各种格式的日志数据。
- channel:source组件把数据收集来以后,临时存放在channel中。用来存放临时数据的——对采集到的数据进行简单的缓存,可以存放在memory、jdbc、file等等。
- sink:sink组件是用于把数据发送到目的地的组件,目的地包括hdfs、logger、avro、thrift、ipc、file、null、hbase、solr、自定义。
于flume可以支持多级flume的agent,即flume可以前后相继,例如sink可以将数据写到下一个agent的source中,这样的话就可以连成串了,可以整体处理了。flume还支持扇入(fan-in)、扇出(fan-out)。所谓扇入就是source可以接受多个输入,所谓扇出就是sink可以将数据输出多个目的地destination中。